Finite Observation
A Spectral Theory of Nonequilibrium Visibility
Abstract
We study finite observation in irreducible finite-state continuous-time Markov nonequilibrium steady states through the local Donsker–Varadhan Hessian at the minimiser . In reduced Fisher coordinates, the nonequilibrium correction factors through the weighted signal operator and the detailed-balance backbone. For rank- orthogonal observation in this reduced Euclidean Fisher geometry, the visible correction is governed by a Ky Fan envelope, with associated retention hierarchy, hidden tail, and weighted stable rank. The envelope hierarchy determines the eigenvalue profile of , equivalently the singular-energy profile and hence the nonzero singular-value magnitudes of . We also identify the optimal orthogonal observer at fixed rank and show that Haar-random rank- observation retains exactly a fraction in expectation. A separate statistical question arises after comparison with the observed detailed-balance backbone: in the compressed-Hessian Gaussian model, distinguishability is governed by a positive shadow operator whose spectrum can differ from the raw visibility spectrum except in special commuting or isotropic-backbone regimes. The weighted geometry further transfers to abstract finite-dimensional metric settings, and hence to the linearised BKM-symmetrised operator setting.
Contents
1 Introduction
1.1 The finite observation problem
A nonequilibrium system may carry irreversibility across many microscopic directions while only a small observable sector is accessible. Hidden transitions, finite time resolution, finite spatial resolution, detector noise, and coarse graining all lead to the same structural question: what can a finite observer actually see of the nonequilibrium fluctuation structure?
In finite-dimensional Markov nonequilibrium steady states, the natural empirical-measure fluctuation object is the local Hessian of the Donsker–Varadhan rate function at its minimiser [1, 2, 3, 4]. A finite observer does not see the full Hessian. The observer only sees its compression to a rank-limited sector. The finite observation problem is therefore precise: given an irreducible nonequilibrium generator and an observable subspace of dimension , how much of the nonequilibrium correction survives projection, and how does that visible share depend on the geometry of the system and the geometry of the observer? The detailed-balance geometry is the reference geometry adopted here for measuring this local Gaussian nonequilibrium correction.
We show that, in the finite-dimensional Markov Gaussian regime treated here, this question reduces to a spectral compression problem in reduced Fisher coordinates. The visible share is governed by a weighted singular-value hierarchy. The hidden share is its spectral tail. The effective complexity of visibility is controlled by weighted stable rank.
1.2 Motivation
Recent work across stochastic thermodynamics, coarse graining, and quantum nonequilibrium theory has made the finite observation problem sharper and more urgent. The literature contains lower bounds on entropy production under partial observation, hidden data, coarse temporal sampling, unresolved transitions, faulty observation maps, and coarse graining [5, 6, 7, 8, 9, 10, 11, 12]. Closely related work studies estimator quality for dissipation under lumping, milestoning, hidden cycles, current fluctuations, and finite statistics, and proposes random or optimised coarse-graining strategies for irreversibility detection [13, 14, 15, 16, 17, 18].
Restricted-information and coarse-grained quantum thermodynamics make the same point from another direction: observation changes the effective thermodynamic description [19, 20, 21, 22, 23]. At a broader level, the thermodynamic uncertainty-relation programme has clarified how much of the field is organised around scalar fluctuation bounds rather than observer-resolved spectral structure [24, 25], and very recent counterexamples show that even two widely used model-free partial-observation bounds, the waiting-time and TUR bounds, admit no universal ordering on the same observed link [26].
What is missing from this landscape, as far as we are aware, is a finite-dimensional law for the visible share of the nonequilibrium correction itself in the Markov Gaussian setting treated here. The current literature is rich in estimators, bounds, and coarse-grained descriptions. The contribution of the present paper is to identify, for orthogonal rank-constrained observers in reduced Euclidean Fisher coordinates, the envelope of the projected Donsker–Varadhan correction, the associated observer-design law at fixed rank, the shadow criterion for observed Gaussian indistinguishability in the compressed-Hessian model, and the corresponding spectral readout of the hidden correction.
1.3 Main claim and conceptual picture
The central claim is that finite observation in the Donsker–Varadhan Gaussian regime has a finite-dimensional spectral normal form. In reduced Euclidean Fisher coordinates, the nonequilibrium correction factors through the reduced skew channel and the detailed-balance backbone via the weighted signal map . Finite observation therefore becomes a rank-constrained orthogonal compression problem for that map.
This leads to two distinct spectral questions. The first is raw visibility: how much nonequilibrium signal survives projection, how much is hidden in the spectral tail, and which observer of rank is best aligned with the signal front. That question is governed by the singular spectrum of and the associated Ky Fan envelope hierarchy. The second is detectability relative to the detailed-balance backbone: once the observed correction is compared to the observed backbone in its natural metric, a second positive operator appears, and its spectrum governs Gaussian distinguishability. These two spectra coincide only in special commuting or isotropic-backbone regimes. The raw and detectability spectra therefore read the same nonequilibrium deviation in two different equilibrium coordinate systems: the ambient detailed-balance backbone, and the backbone induced on the observed sector after projection. Raw nonequilibrium signal and statistically detectable nonequilibrium signal therefore need not live in the same observer directions. The theory therefore distinguishes directions that are structurally invisible under the observation map from directions that remain visible in principle but are weak or poorly aligned in the observable geometry.
Within the orthogonal-observer model used here, the paper gives a finite-dimensional theory of visibility, observer design, detectability, and spectral readout. The bridge theorem identifies the structure of the correction, the envelope gives the visible law, the shadow gives the distinguishability law, and the full hierarchy recovers the singular-energy profile of the correction, equivalently the nonzero singular-value magnitudes of .
1.4 Main results
The first result is the bridge theorem. We prove that the Donsker–Varadhan correction is quadratic in the reduced skew channel. This is the representation step that turns the fluctuation problem into a weighted operator problem.
The second result is the finite-observation law. For every orthogonal rank-constrained observer, the visible nonequilibrium content is given by a Ky Fan envelope of the weighted signal map. The retention hierarchy, hidden tail, and weighted stable rank follow from this representation.
The third result is the observer-design law. Visible signal is an alignment score against the left singular modes of the weighted signal map. This yields the optimal orthogonal observer, its gap-controlled uniqueness criterion, the worst observer, and the Haar-random rank- baseline in expectation.
The fourth result is the two-spectrum theorem. The observed Gaussian law in the compressed-Hessian model is governed by a positive shadow operator, and backbone whitening yields a second spectral hierarchy for detectability relative to the detailed-balance backbone. In general this detectability spectrum is distinct from the raw visibility spectrum.
The fifth result is spectral completeness of the envelope hierarchy for magnitudes. The full envelope hierarchy recovers the ordered singular-energy profile , equivalently the eigenvalue profile of , and hence the nonzero singular-value magnitudes of .
The sixth result is a transfer theorem. The weighted envelope, alignment, detectability, and spectral-readout structure transfer to abstract finite-dimensional metric settings and hence to linearised BKM operator geometry.
1.5 Contribution
The paper gives a finite-dimensional solution to the finite-observation problem in the Markov Gaussian regime treated here. Its contribution is to identify the operator geometry that organises what finite observers can still see within the orthogonal-observer model.
More specifically, it proves a bridge from the skew sector to the fluctuation correction, a rank-constrained envelope law, an observer-design law with a Haar baseline, a Gaussian shadow criterion, a second spectrum for detectability distinct from raw visibility, and an envelope hierarchy that determines the singular-energy profile of the correction and hence the singular-value magnitudes of .
1.6 Roadmap
Section 2 fixes the finite-dimensional Markov setting, the Fisher normal form, the notion of a finite observer, and the observable normal-form language. Section 3 proves the bridge theorem and identifies the nonequilibrium correction as a positive correction operator together with its weighted signal factorisation. Section 4 derives the finite-observation law: the Ky Fan envelope, retention hierarchy, hidden tail, stable-rank obstruction, and the direct-sum allocation reading of the envelope.
Section 5 develops the observer-design layer through the alignment theorem, optimal and worst observers, and the Haar-random baseline. Section 6 proves the shadow and detectability theory, making explicit the split between raw visibility and backbone-normalised distinguishability, and includes a fixed-channel Gaussian noisy-observation extension. Section 7 proves spectral completeness of the envelope hierarchy for singular-value magnitudes and develops the induced observability order between systems.
2 Setting and observable normal forms
2.1 Finite-dimensional Markov nonequilibrium steady states
Let be a finite state space, and let be the generator of an irreducible continuous-time Markov chain on . Thus for , for each , and irreducibility guarantees a unique stationary law
| (2.1) |
satisfying . We are interested in the nonequilibrium steady-state case, meaning that need not satisfy detailed balance with respect to .
Throughout the paper we work at the level of stationary empirical-measure fluctuations. The fluctuation object in this setting is the local Hessian of the Donsker–Varadhan rate function at its minimiser , viewed in the Fisher geometry associated with the stationary law. This Fisher viewpoint is not merely convenient notation: in nonequilibrium stochastic thermodynamics it has a direct geometric and physical interpretation, and in the reversible Markov setting it sits on a well-developed information-geometric background [27, 28]. The detailed-balance geometry provides the reference unit system in which the Gaussian nonequilibrium correction is measured. The entire finite-observation theory developed below takes place in the tangent space at , after passing to the Euclideanised Fisher coordinates adapted to that geometry.
Let
| (2.2) |
The Euclideanised Fisher tangent space is
| (2.3) |
Equivalently, is the codimension-one subspace orthogonal to the stationary direction in Fisher coordinates. We denote by
| (2.4) |
the orthogonal projector onto .
The Fisher metric in density coordinates becomes the standard Euclidean inner product after this transformation, so from this point onward all orthogonality, projection, adjoints, and singular values in the classical Markov setting are taken with respect to the Euclidean structure on , unless stated otherwise.
2.2 Fisher geometry and the normal form
Define the Fisher-conjugated generator
| (2.5) |
Its restriction to the tangent space carries the full linearised stationary fluctuation geometry. Since is -invariant, we may regard
| (2.6) |
as an operator on .
The central structural decomposition is the Fisher normal form
| (2.7) |
where
| (2.8) |
Thus is self-adjoint and is skew-adjoint on . In the present work, is the dissipative backbone and is the skew, antisymmetric sector carrying the nonequilibrium part relative to the detailed-balance backbone. This symmetricantisymmetric normal-form viewpoint is consonant with earlier steady-state fluctuation analyses of driven diffusions [29] and with the network-cycle description of nonequilibrium steady states originating in Schnakenberg theory [30]. The detailed-balance reference object is obtained by setting while keeping the same stationary law and dissipative geometry.
The nonequilibrium correction to the Donsker-Varadhan Hessian will be shown in Section efsec:exact-dv-bridge to be carried entirely by the skew sector after the reduced-coordinate analysis, while the observed detailed-balance backbone is governed by the projected dissipative sector.
To work concretely, choose an orthonormal matrix
| (2.9) |
whose columns form an orthonormal basis of . Then
| (2.10) |
Reduced coordinates are identified with tangent vectors by . In these coordinates the Fisher-conjugated generator becomes
| (2.11) |
with corresponding reduced decomposition
| (2.12) |
All finite-dimensional statements in the main text will be expressed on this reduced Euclidean space. For notational simplicity, we will often suppress the distinction between the operator on and its matrix in reduced coordinates when no ambiguity arises. Where the reduced-coordinate nature matters, hats will be retained. This dissipative-plus-skew normal form already foreshadows the later operator-space transfer, where the same structural split reappears in metric operator geometry.
2.3 Observable sectors and finite observers
A finite observer is modelled by a rank-constrained orthogonal projector on the reduced Fisher space. Concretely, let
| (2.13) |
be a Euclidean orthogonal projector of rank , and let
| (2.14) |
The rank is the observable dimension. It is the number of independent fluctuation directions actually accessible to the observer.
This choice of projector is the mathematical form of finite observation used here. It covers rank-constrained observable sectors, reduced coordinates, compressions to slow manifolds, and more abstract finite-resolution measurement ideals, provided the observation is represented by orthogonal compression in the underlying Euclideanised geometry. The exact envelope law proved below is for orthogonal rank- observers in this sense. More general coarse-graining maps require different machinery, with the fixed-channel Gaussian noisy-observation section giving one controlled extension. Later sections will explain how this structure extends to weighted operator-space settings, where orthogonality is taken with respect to a nontrivial metric.
Given , the observer does not see the full operator , the full detailed-balance Hessian, or the full Donsker-Varadhan Hessian. The observer sees only their compressions to . The finite observation problem is therefore a rank-constrained compression problem on a fluctuation operator whose full structure is initially hidden.
2.4 Projected observable normal forms
The projected observable normal form associated with is
| (2.15) |
where is the Euclidean metric restricted to , and
| (2.16) |
This is the observable quadruple inherited by finite observation from the full Markov generator.
Observable equivalence is governed by such projected data once the finer nonequilibrium correction is sufficiently small. The work proves a stronger result. The projected quadruple is the observable backbone of a signal theory in which the nonequilibrium correction is placed in weighted spectral form and its visible share under is determined explicitly.
Three levels of observable structure will later reappear:
-
1.
the purely metric or static level, carried by and ,
-
2.
the dissipative level, carried by ,
-
3.
the full projected normal form, carried by .
The theory developed below refines this hierarchy by inserting one more object: the projected nonequilibrium correction to the Donsker-Varadhan Hessian. That correction is the signal of hidden irreversibility.
2.5 The Donsker-Varadhan Hessian as the fluctuation object
Let denote the Donsker-Varadhan rate function for the empirical measure of the irreducible Markov chain generated by . Since is the unique stationary law, is the minimiser of , and the Hessian of at is positive definite on the reduced tangent space. We denote this Hessian in reduced Euclidean coordinates by
| (2.17) |
The canonical detailed-balance reference is obtained by Fisher symmetrisation. Let
| (2.18) |
Then has the same stationary law , satisfies detailed balance with respect to , and has reduced Fisher generator . The corresponding detailed-balance Hessian on the reduced Euclidean Fisher space is therefore
| (2.19) |
Because the detailed-balance reference is irreducible, is positive definite on the reduced space, so and is therefore invertible there. Under this sign convention, the positive conductance form is represented by . The nonequilibrium correction is
| (2.20) |
At this point, is only a definition. The bridge section then identifies it as a positive correction operator built from the skew sector and the detailed-balance backbone.
The object of interest is not entropy production by itself, nor the full rate function, nor a pathwise current observable. It is the fluctuation-side nonequilibrium correction encoded in . Once that correction is understood, finite observation becomes a problem of spectral retention.
3 The Donsker-Varadhan bridge
3.1 Reduced coordinates and the conductance identity
The bridge from the Donsker-Varadhan variational principle to the spectral theory developed later in the paper passes through a reduced-coordinate quadratic envelope. The full derivation is carried out in Appendix A. Here we isolate the structural cancellation that drives everything that follows.
Starting from the variational representation of the Donsker-Varadhan rate function, one introduces reduced logarithmic coordinates near stationarity and expands the envelope to second order. This produces a reduced quadratic fluctuation problem governed by two coupled ingredients. One is a current-like reduced operator carrying the skew dependence. The other is a reduced conductance matrix controlling the quadratic envelope itself. A priori, both the dissipative and skew sectors could have entered that conductance matrix.
They do not. The skew sector contributes no quadratic form of its own, so the conductance matrix of the full nonequilibrium envelope depends only on the dissipative backbone. This is the reason the final bridge is purely quadratic in the skew channel, with no mixed dissipative-skew leakage.
Let denote the reduced conductance matrix produced by the full nonequilibrium envelope construction, and let denote the corresponding reduced conductance matrix for the detailed-balance reference problem obtained by suppressing the skew sector. Both objects are defined canonically by the same reduced-coordinate construction; the explicit formulas are recorded in Appendix A.
Proposition 3.1 (Reduced conductance identity).
In the finite-dimensional irreducible Markov setting described above, the reduced conductance matrix of the full Donsker-Varadhan quadratic envelope coincides with that of the detailed-balance reference problem:
| (3.1) |
Equivalently, the quadratic conductance controlling the reduced Donsker-Varadhan Hessian depends only on the dissipative sector and is blind to the skew sector.
Proof.
Write the Donsker–Varadhan variational formula as [1, 2, 3]
| (3.2) |
Choose reduced Fisher coordinates and reduced logarithmic coordinates by
| (3.3) |
Using the second-order reduced-coordinate expansion derived in Appendix LABEL:app:reduced-coordinate-identities gives the reduced quadratic envelope
| (3.4) |
where . The key point is that the pure quadratic term in is
| (3.5) |
because for every skew-symmetric matrix . Hence the conductance block is determined entirely by , and the nonequilibrium reduced conductance coincides with the detailed-balance one. Equivalently,
| (3.6) |
The skew sector survives only in the current block . ∎
Proposition 3.1 records the key asymmetry used in the bridge argument. The skew sector drives the nonequilibrium correction, but the quadratic conductance beneath the reduced envelope is controlled by the dissipative geometry alone. This is why the later factorisation of the correction is so rigid. The skew sector enters through a weighted signal map, but the weight itself is fixed by the detailed-balance backbone. The first antisymmetry input here is the identity , but the bridge theorem uses it inside the Legendre contraction, where the supremum over removes the mixed dissipative-skew contribution at Hessian order. This cancellation is a level-2 empirical-measure statement, and should not be read as a statement about the unreduced level-2.5 fluctuation Hessian.
The rest of Section 3 exploits this asymmetry. The next subsection converts the reduced envelope into a quadratic representation of the nonequilibrium correction, which in turn becomes the signal operator governing finite observation.
Remark (Dirac-type factorisation of the DV Hessian).
The bridge identity also admits a canonical first-order factorisation, using the principal positive square root of . Define
| (3.7) |
Since is skew-symmetric, one has
| (3.8) |
and therefore
| (3.9) |
Thus exactly. Since on the reduced space, , so is invertible. The operator packages the detailed-balance backbone and the reduced skew channel into a single first-order object whose adjoint square recovers the full nonequilibrium fluctuation Hessian.
3.2 Quadraticity of the nonequilibrium correction
We now progress to the central bridge theorem. Proposition 3.1 implies that the reduced Donsker-Varadhan quadratic envelope is built on the detailed-balance conductance matrix alone. The skew sector therefore enters only through the reduced current channel. This yields a quadratic representation of the nonequilibrium correction.
To state the result cleanly, recall from Section 2 that the canonical detailed-balance reference is the Fisher-symmetrised one, with reduced Hessian
| (3.10) |
Let denote the canonical reduced skew channel produced by the reduced-coordinate envelope construction. The next theorem is the finite-dimensional bridge identity that identifies the fluctuation correction as a positive correction operator with an explicit weighted signal factorisation.
Theorem 3.2 (Quadraticity of the DV correction).
In the finite-dimensional irreducible Markov setting of Section 2, the Donsker-Varadhan Hessian decomposes as
where the nonequilibrium correction is
Equivalently, is positive semidefinite and is quadratic in the reduced skew channel with no mixed dissipative-skew term.
Proof.
By Proposition 3.1 and the reduced-coordinate expansion recalled above, the second-order reduced envelope has the form
| (3.11) |
Set
| (3.12) |
Then is positive definite on the reduced space and
| (3.13) |
using . Completing the square in gives
| (3.14) |
Taking the supremum over , exactly as in the reduced variational contraction derived in Appendix LABEL:app:reduced-coordinate-identities, yields
| (3.15) |
Since ,
| (3.16) |
Therefore
| (3.17) |
By definition of the reduced Hessian,
| (3.18) |
so
| (3.19) |
For the detailed-balance reference , the same reduced envelope gives
| (3.20) |
Hence , and substitution gives
| (3.21) |
Equivalently,
| (3.22) |
The Gram form
| (3.23) |
implies positive semidefiniteness. ∎
Remark (Orthogonal invariance of the quadratic correction).
The identity of Theorem 3.2 is invariant under orthogonal changes of reduced Euclidean Fisher coordinates. In particular, the spectrum of , and therefore every envelope, retention, and spectral-readout quantity derived from it, is coordinate-independent within the reduced Euclidean Fisher coordinates fixed by the paper.
Theorem 3.2 identifies as an explicit positive correction operator with a weighted signal factorisation at the level of the quadratic fluctuation correction. Once the detailed-balance backbone is fixed, the reduced skew channel determines the Gaussian nonequilibrium excess at Hessian order, with no additional mixed dissipative-skew term surviving in this reduced setting.
Two immediate consequences are worth recording.
Corollary 3.3 (Positivity and rank control).
The nonequilibrium correction is positive semidefinite. Moreover,
| (3.24) |
and the range of is exactly the signal subspace generated by the reduced skew channel.
Proof.
Positivity follows from Theorem 3.2. Since is invertible,
| (3.25) |
Now set . Then
| (3.26) |
and . Hence
| (3.27) |
The range statement follows from , since , and because is invertible. ∎
Corollary 3.4 (Detailed-balance characterisation).
The following are equivalent:
-
1.
the generator is detailed-balance in the Fisher normal form, that is, ,
-
2.
the reduced skew channel vanishes, that is, ,
-
3.
the Donsker-Varadhan Hessian equals its detailed-balance reference, that is, .
Proof.
The equivalence of the first two statements is by construction of the reduced skew channel. The equivalence of the second and third follows from Theorem 3.2 and the positive definiteness of . ∎
3.3 Basis transport and the weighted signal operator
The exact quadraticity theorem immediately suggests the right signal object. Since is positive definite, define
| (3.28) |
Then
| (3.29) |
This is the weighted signal operator of the paper, and is its induced positive correction operator.
The factorisation is conceptually simple but extremely strong. It says that the nonequilibrium correction is a covariance-type signal built from the skew channel after whitening by the detailed-balance Hessian. The dissipative sector therefore enters twice.
First, it provides the detailed-balance backbone . Second, it defines the metric in which the skew contribution is whitened and measured. At the level of currents and affinities, the cycle origin of this skew contribution is the same identified in Schnakenberg network theory and its fluctuation-theorem extension [30, 31].
To put the operator in its most transparent form, we diagonalise the detailed-balance backbone. Since is real symmetric positive definite, there exists an orthogonal matrix and positive eigenvalues
| (3.30) |
such that
| (3.31) |
In this basis the weighted signal operator is
| (3.32) |
Thus the visible nonequilibrium signal is obtained by taking the skew sector in the eigenbasis of the detailed-balance Hessian and weighting each channel by the inverse square root of the corresponding detailed-balance stiffness.
This observation is the structural source of the stable-rank and envelope theory developed in Section 4. The relevant quantity is not the raw skew operator by itself. It is the skew operator after whitening by the detailed-balance geometry.
The factorisation also makes clear how the theory refines the unweighted signal picture. In the unweighted Euclidean setting, singular-energy retention is attached directly to an input operator. Here the physically relevant input operator is not alone but its Hessian-whitened version . The unweighted theory therefore appears as the unweighted shadow of the final weighted theory.
3.4 Slow observable block and converter structure
We now make precise the slow-block structure that underlies projection suppression and explains the intrinsic-slow and mixed-return channels.
Fix a rank- observable projector and identify its range with the slow observable sector. For the block formula below we assume that is -invariant, equivalently that commutes with . In physical terms, this means that the observed sector is aligned with detailed-balance relaxation modes, so the backbone is block diagonal across observed and hidden directions. Let denote its orthogonal complement in the reduced Euclidean space. Relative to the decomposition
| (3.33) |
write
| (3.34) |
The notation stands for slow or observed, while stands for fast or hidden. The block diagonal form of is the content of the -invariance assumption. Since is skew-symmetric, its blocks satisfy
| (3.35) |
The quadraticity theorem then gives a decomposition of the observed nonequilibrium correction on such spectral observable sectors.
Theorem 3.5 (Exact block formula on -invariant observed sectors).
Assume that the observable sector is -invariant. With notation as above, the slow observable block of the nonequilibrium correction is
| (3.36) |
Equivalently, relative to the chosen -adapted block decomposition , the observed correction splits into an intrinsic slow block and a hidden-return block from the complementary sector.
Proof.
Block-decompose the quadraticity formula of Theorem 3.2 relative to the orthogonal splitting . Because is -invariant, is block diagonal in the chosen basis, hence so is . The -block of
| (3.37) |
is therefore exactly
| (3.38) |
Multiplying by gives the result. ∎
Theorem 3.5 is the precise algebraic form of the observed block structure on -adapted sectors. The invariant observable object is the compressed correction . Relative to the chosen -adapted splitting, the first term is the intrinsic slow correction generated entirely within the observed sector, while the second term is the hidden return from complementary directions into the observed sector, weighted by the inverse stiffness of the fast detailed-balance backbone. For a general non--invariant projector one still has the compressed correction , but not this simple block formula.
This formula is already enough to recover the structural content of projection suppression under slow-fast structural hypotheses. If the slow skew block is weak and the mixed return channel is either weak or heavily penalised by a stiff fast backbone, then the observed correction is small. But now this is no longer a theorem about disappearance under an external list of assumptions. It is the direct block-level anatomy of the correction.
The converter formula also reveals the correct physical interpretation of the fast backbone. A large fast detailed-balance stiffness suppresses the mixed return channel because the hidden sector becomes expensive as a route for observable nonequilibrium correction. This is the direct finite-dimensional mechanism behind fast-block coercivity.
We record the most basic consequence.
Corollary 3.6 (Fast-block coercive bound).
Assume that the fast detailed-balance block satisfies
| (3.39) |
for some . Then
| (3.40) |
In particular, the mixed return channel is suppressed by increasing fast-sector coercivity.
Proof.
Since , one has . Conjugating by preserves positive-semidefinite order and yields the claim. ∎
Corollary 3.6 is intentionally elementary. The point is not to optimise constants here. The point is to expose the mechanism. The fast hidden sector suppresses observable nonequilibrium not by magic, but because the bridge weights hidden return channels by the inverse fast detailed-balance stiffness.
3.5 Interpretation
Section 3 identifies the nonequilibrium correction as a positive weighted correction operator carried by the skew channel and generated by the weighted signal operator whitened by the detailed-balance backbone.
This changes the logic of the entire theory. Once
| (3.41) |
is known, finite observation becomes a problem of signal retention under orthogonal compression. The observer does not interact directly with the full generator, nor with the full rate function, but with a positive signal operator whose singular-energy content can be tracked.
Structural suppression and unweighted comparison can now be re-read from this point of view. Observable structure collapses to a projected normal form once the nonequilibrium correction becomes negligible under compression, and the singular-value mechanism behind optimal retention and rank-limited visibility becomes exact once the bridge theorem identifies the correct weighted signal operator.
The next section turns that signal into the observable envelope, the retention hierarchy, and the stable-rank complexity measure governing finite observation within the orthogonal-observer class.
In this form the finite-observation anatomy can be read cleanly in four layers. The algebraic source of the correction is the reduced skew channel . The signal actually compressed by finite observation is the backbone-weighted operator . On -adapted observed sectors, the hidden contribution appears explicitly through the mixed return block . At fixed observable rank , the optimally hidden budget is the singular-energy tail of , while statistical detectability after whitening is governed by a second spectrum and should not be conflated with raw visible mass.
4 The observable envelope
4.1 Visible nonequilibrium signal of a finite observer
Section 3 identified the nonequilibrium correction as the positive signal operator
| (4.1) |
We now solve the finite observation problem for this signal. This section is about raw visibility: how much nonequilibrium signal survives rank-constrained orthogonal compression, how much is hidden in the spectral tail, and how the observation budget should be allocated across decoupled sectors. Statistical distinguishability relative to the detailed-balance backbone is a different question and is deferred deliberately to Section 6.
Let be a rank- orthogonal projector on the reduced Euclidean Fisher space. The observer sees only the compression of to the -dimensional sector . The natural scalar measure of visible nonequilibrium content is therefore
| (4.2) |
This quantity is the observable nonequilibrium signal retained by . It is the total projected singular energy of the DV correction that survives finite observation.
The first theorem of the section shows that has an exact projector formula.
Theorem 4.1 (Exact projector formula for orthogonal observers).
For every orthogonal projector on the reduced Euclidean Fisher space,
| (4.3) |
Equivalently, the visible nonequilibrium content retained by is the projected Frobenius energy of the weighted signal operator within the orthogonal-observer class fixed in this paper.
Proof.
Using the exact weighted Gram form from Theorem 3.2,
| (4.4) |
Hence
| (4.5) |
Since is an orthogonal projector,
| (4.6) |
This gives the claimed formula. ∎
Remark (Orthogonal-basis invariance of visible signal).
Under an orthogonal change of reduced Euclidean Fisher basis, and , the value is unchanged. Thus the visible signal is an invariant of the orthogonal observer class, not of a particular coordinate representative.
Theorem 4.1 is the first answer to the finite observation question. Once the bridge has been closed, the visible nonequilibrium signal of an orthogonal observer is no longer a vague statement about how much correction survives. It is a projected energy.
This theorem also turns finite observation into an optimisation problem over rank-constrained subspaces. The next subsection solves that problem.
4.2 Optimal retained signal at fixed observable dimension
Fix an observable dimension . Among all rank- orthogonal projectors, some will retain very little of the DV signal, while others will retain as much as possible. The optimal value is given by the Ky Fan top-singular-energy envelope of [32, 34].
Let
| (4.7) |
denote the singular values of , counted with multiplicity and extended by zeros if needed. Define
| (4.8) |
Theorem 4.2 (Exact weighted Ky Fan envelope for orthogonal rank- observers).
For each , among orthogonal rank- projectors on the reduced Euclidean Fisher space,
| (4.9) |
The supremum is attained by the orthogonal projector onto the span of the top left singular vectors of . This is a global optimum over the orthogonal rank-constrained observer class fixed in the paper.
Proof.
By Theorem 4.1,
| (4.10) |
Write the singular value decomposition
| (4.11) |
where . Since left multiplication by an orthogonal matrix preserves projector rank and Frobenius norm, maximising over rank- projectors is equivalent to maximising , where is again a rank- orthogonal projector.
The quantity is the sum of the squares of the singular values weighted by the diagonal entries selected by the projector. By the Ky Fan maximum principle and its modern matrix-analytic formulation [32, 34], the maximum is obtained by projecting onto the span of the first coordinate directions, giving
| (4.12) |
Multiplying by yields the result. ∎
Proposition 4.3 (Lipschitz stability of the envelope values).
Let and be positive semidefinite corrections on the same reduced Euclidean Fisher space, and let and denote the corresponding orthogonal rank- envelopes. Then for every ,
| (4.13) |
In particular, the envelope values are stable under operator perturbation.
Proof.
Theorem 4.2 is the finite-dimensional visibility law at fixed observable rank. It says that the best possible orthogonal -dimensional observer captures exactly the top singular energies of the weighted signal operator.
This identifies the optimal rank- orthogonal observer within the reduced Euclidean Fisher geometry. It is the observer aligned with the top singular front of the weighted signal operator.
Corollary 4.4 (Worst retained signal).
Let be the dimension of the reduced Euclidean Fisher space, and extend the singular-value list of to length by zeros. Then the minimum visible nonequilibrium signal over rank- orthogonal projectors is
| (4.14) |
In particular, if , then the minimum is zero.
Proof.
Apply the Ky Fan minimum principle to the positive semidefinite operator , or equivalently to the squared singular values of padded by zeros to the ambient reduced dimension . The worst rank- projector retains the bottom singular energies. ∎
Corollary 4.4 will later be useful when we discuss generic observers, bad alignment, and visibility intervals.
4.3 Retention fraction and hidden fraction
The envelope determines not only the best retained amount, but also the fraction of the total signal that survives at observable dimension .
Define the total nonequilibrium signal by
| (4.15) |
For each , define the retention fraction
| (4.16) |
whenever . Then
| (4.17) |
The complementary hidden fraction is
| (4.18) |
Corollary 4.5 (Exact retention and hidden fractions for the optimal orthogonal rank- envelope).
Assume . Then for every observable dimension ,
| (4.19) |
In particular, the hidden nonequilibrium content is the singular-energy tail of the weighted signal operator.
Proof.
This is immediate from Theorem 4.2 and the definition of . ∎
Corollary 4.5 shows that finite observation of nonequilibrium is a cumulative singular-energy problem. The visible share is the cumulative front, and the hidden share is the tail. The retention fraction is the fraction of the weighted DV signal retained by the best rank- orthogonal observer.
4.4 Weighted stable rank as the complexity invariant
The retention hierarchy of Corollary 4.5 gives rise to a natural complexity proxy for the paper.
Definition 4.6 (Weighted stable rank).
The weighted stable rank of the nonequilibrium signal is
| (4.20) |
for nonzero .
This is the stable-rank or numerical-rank functional applied to the weighted signal operator in the geometry [35]. This quantity is the effective dimensionality of the weighted nonequilibrium signal. It measures how many singular directions are genuinely carrying signal, after weighting by the detailed-balance geometry.
If , then , every envelope value vanishes, and the finite-observation problem is trivial because there is no nonequilibrium signal to retain.
A low stable rank means that the nonequilibrium correction is concentrated. A small number of observable directions can recover a large fraction of it. A high stable rank means that the correction is diffuse and spread across many directions. In that case, finite observers are forced to miss most of the signal unless their rank is correspondingly large.
The next theorem makes this precise.
Theorem 4.7 (Stable-rank obstruction).
Assume . Then for every ,
| (4.21) |
Equivalently, to retain at least fraction of the nonequilibrium signal, any observer must satisfy
| (4.22) |
Proof.
By definition of stable rank,
| (4.23) |
Since the singular values are non-increasing,
| (4.24) |
Therefore
| (4.25) |
Rearranging gives the necessary rank condition for retaining at least fraction . ∎
Theorem 4.7 is the scalar obstruction governing finite observation. Weighted stable rank is a useful nonequilibrium complexity proxy, but it is not a complete descriptor of the envelope hierarchy. It gives a first-order visibility bound rather than a sufficient statistic for the full retention curve.
The literature on partial observation often organises itself around estimator performance, signal-to-noise ratio, missing transitions, or lower bounds on hidden entropy production. Those are all useful, but they do not by themselves isolate the intrinsic dimensional difficulty of the weighted nonequilibrium signal. Weighted stable rank supplies a coarse measure of that difficulty.
4.5 Sharp consequences
The envelope and stable-rank law immediately give several structural consequences in finite dimensions.
Corollary 4.8 (Observability criterion).
Assume . Then the following are equivalent for a given observable dimension :
-
1.
there exists a rank- orthogonal observer in the reduced Euclidean Fisher space that sees the entire nonequilibrium signal,
-
2.
,
-
3.
.
Proof.
The equality means that all nonzero singular energies are contained in the first modes, which is equivalent to . In that case, projection onto the span of all left singular vectors with nonzero singular value retains the entire signal. ∎
Corollary 4.9 (Blind-observer threshold).
Let
| (4.26) |
Then a rank- observer can be completely blind to the nonequilibrium correction, meaning
| (4.27) |
if and only if
| (4.28) |
Equivalently, a -dimensional blind observer exists if and only if the observable sector can be placed entirely inside .
Proof.
By Corollary 4.4 and the visibility interval,
| (4.29) |
where are the eigenvalues of in nonincreasing order, padded by zeros. This minimum vanishes if and only if the bottom eigenvalues are zero, which is equivalent to
| (4.30) |
∎
Corollary 4.10 (One-mode visibility).
Assume . Then the maximal rank-one visible fraction is
| (4.31) |
Thus the inverse stable rank is the best one-mode visibility of the nonequilibrium signal.
Proof.
By definition,
| (4.32) |
∎
Corollary 4.10 gives perhaps the most immediate interpretation of the weighted stable rank. It tells us how visible the nonequilibrium signal is to the best possible one-dimensional observer.
Corollary 4.11 (Envelope monotonicity and concavity).
The sequence is non-decreasing and discretely concave:
| (4.33) |
Equivalently, the marginal gain from increasing the observer dimension decreases monotonically with rank.
Proof.
This follows immediately from the representation
| (4.34) |
since the increments are the non-increasing sequence . ∎
Corollary 4.11 has a useful interpretation. The first few observable directions are the most valuable. Beyond that, one enters the diminishing-returns regime governed by the singular-energy tail.
We also note the residual form.
Corollary 4.12 (Optimal hidden tail).
The minimal hidden nonequilibrium signal after the best rank- observation is
| (4.35) |
Proof.
Subtract the envelope from the total signal. ∎
Corollary 4.12 shows that finite observation has an optimal truncation error. This will later become the basis of the spectroscopy theorem.
Proposition 4.13 (Equality in the stable-rank obstruction).
Assume , and let
| (4.36) |
Then
| (4.37) |
is an equality if and only if
| (4.38) |
The analogous statement holds for the detectability retained fraction after replacing by .
Proof.
Since
| (4.39) |
the stable-rank bound is equivalent to
| (4.40) |
Equality holds if and only if . The detectability statement is identical after replacing the raw signal operator by the backbone-whitened signal operator. ∎
4.6 Comparison with unweighted signal geometry
A prior unweighted analysis of rank-limited visibility in a Euclidean setting did not yet include the Donsker-Varadhan bridge or the Hessian whitening. The theory contains that picture as an unweighted shadow.
The point is simple. In the final weighted theory, the physically relevant signal is
| (4.41) |
not by itself. The role of the unweighted Euclidean hierarchy is therefore to capture the same signal-retention geometry before the dissipative weighting is inserted. Once the bridge is known, the correct signal is no longer the raw skew channel but the skew channel whitened by the detailed-balance Hessian.
This relationship can be quantified directly. Let
| (4.42) |
Since
| (4.43) |
one obtains the operator inequalities
| (4.44) |
Consequently, if denotes the unweighted rank- singular-energy envelope attached to , equivalently the Ky Fan envelope of , then
| (4.45) |
Proposition 4.14 (Comparison with the unweighted envelope).
The weighted DV envelope is sandwiched between the old unweighted skew singular-energy envelope, scaled by the spectral window of the detailed-balance Hessian:
| (4.46) |
Proof.
From
| (4.47) |
and the positive-semidefinite order bounds on , one gets
| (4.48) |
Multiplying by gives the corresponding comparison for . Taking the optimal rank- compressed traces on both sides yields the stated envelope bounds. ∎
Proposition 4.14 is important for the internal logic of the theory. It shows that the unweighted Euclidean envelope is the unwhitened skeleton of the final weighted signal geometry, and it quantifies its precise relationship to the full theory.
At this point the finite observation problem has been solved at the level of retained amount, retained fraction, and complexity obstruction. The next section turns to the geometry of observer quality. Visible nonequilibrium becomes a question of alignment between the observer and the singular directions of the weighted signal operator.
5 Alignment, optimal observers, and generic observers
5.1 The alignment theorem
Section 4 solved the rank-constrained visibility problem at the level of optimal retained signal. We now refine that result by identifying the geometric mechanism behind observer quality.
Let
| (5.1) |
be a singular value decomposition of the weighted signal operator, where
| (5.2) |
are the nonzero singular values, the vectors form an orthonormal family of left singular directions in the reduced Euclidean Fisher space, and the vectors form an orthonormal family of right singular directions. The finite observation problem concerns how a rank-constrained projector couples to the left singular directions , since these are the visible directions of the positive signal operator
| (5.3) |
The answer is given by the following theorem.
Theorem 5.1 (Alignment theorem for orthogonal observers).
For every orthogonal projector ,
| (5.4) |
Equivalently, the visible nonequilibrium signal retained by is a weighted alignment score between the observer and the left singular directions of the weighted signal operator.
Proof.
Starting from the projector formula of Theorem 4.1,
| (5.5) |
Insert the singular value decomposition:
| (5.6) |
Since the form an orthonormal family, the Frobenius norm squares add:
| (5.7) |
Multiplying by gives the claim. ∎
Remark (Degenerate singular subspace ambiguity in the alignment theorem).
If the singular spectrum of has degeneracies, the left singular directions are defined only up to orthogonal rotation inside each degenerate singular subspace. The theorem should therefore be read at the level of the corresponding invariant subspace. What is canonical is the invariant subspace itself, together with the corresponding weighted sum on that subspace, not any individual basis vector inside a degenerate block.
Theorem 5.1 is one of the central structural identities of the paper. It shows that visible nonequilibrium is not determined by rank alone. Rank fixes the size of the observer, but the actual retained signal is controlled by how the observer aligns with the singular-energy front of .
This point deserves emphasis. A poor observer need not be too small; it can be misaligned. A coarse observer can outperform a finer one if it captures a larger weighted overlap with the dominant singular directions. In the language of the partial-observation literature, observer geometry matters as much as observer size [13, 6, 7, 8, 36].
The alignment theorem also makes the finite-observation picture more precise. The singular-energy levels measure the available weighted signal energy in each mode, while the factors measure the observer’s access to those modes. The visible nonequilibrium signal is the product of these two ingredients, summed over modes.
5.2 Optimal observer design
The Ky Fan envelope theorem already identified the maximal retained signal at fixed rank. We now restate that result in the language of observer design. This is an immediate design corollary of the envelope law and the alignment formula, and it is central to the final paper.
Corollary 5.2 (Optimal orthogonal rank- observer).
Fix an observable dimension . Let
| (5.8) |
where are the top left singular directions of . Let be the orthogonal projector onto . Then
| (5.9) |
and is an optimal rank- observer.
If the singular value is strictly larger than , then is uniquely determined. More generally, let . Every optimal orthogonal rank- observer must contain the full direct sum of left-singular eigenspaces with singular value strictly larger than , and the remaining dimension may be chosen arbitrarily inside the eigenspace for . This is the only freedom coming from degeneracy.
Proof.
By Theorem 4.2, the optimal retained signal at rank is
| (5.10) |
For the projector , one has
| (5.11) |
when there is no degeneracy across the -th cutoff, and the alignment theorem then gives
| (5.12) |
The uniqueness statement is standard from the Ky Fan maximum principle [32, 34]. If the cutoff singular value is isolated, the top -dimensional left singular subspace is unique. If there is degeneracy, every optimal -plane must contain the full direct sum of left-singular eigenspaces with singular value strictly larger than the cutoff, and only the remaining dimension is free inside the eigenspace at the cutoff. This is exactly the equality case in the Ky Fan principle [32, 34]. ∎
Corollary 5.2 identifies the best orthogonal finite observer for nonequilibrium detection in the Gaussian fluctuation setting.
Most recent work asks how much irreversibility can be inferred from a given partial observation scheme [5, 13, 6, 7, 36]. The corollary answers the stronger question within the orthogonal rank-constrained class: for a fixed observational budget , which observable sector retains the most nonequilibrium signal? The answer is at the level of optimal value, and unique at the subspace level only when the cutoff spectral gap is open.
Corollary 4.4 gives the complementary minimum retained signal at fixed rank. Finite observation therefore comes with both a best observer and a worst observer, and the spread between them is the first visibility interval for the DV correction.
Remark (Gap-dependent subspace stability).
The optimal value is stable under perturbation by Proposition 4.3, but the optimal subspace is stable only when the cutoff spectral gap is positive. In the gapless case the optimal value remains stable, while the optimal -plane need not be unique.
5.3 Worst-case and generic observation
The best and worst rank- observers define the two extremes of finite observation at fixed observable dimension. Between those extremes lies the generic case. We now identify the natural baseline for generic observation.
Let
| (5.13) |
be the dimension of the reduced Euclidean Fisher space. A rank- orthogonal projector is called Haar-random if its range is distributed uniformly on the Grassmannian . Such a projector is the natural model for an unstructured observer of dimension .
The following proposition gives the generic baseline in expectation.
Proposition 5.3 (Haar-random orthogonal-observer baseline in expectation).
Let be Haar-random among rank- orthogonal projectors on the -dimensional reduced Euclidean Fisher space. Then
| (5.14) |
and therefore
| (5.15) |
Equivalently, the expected retained fraction of a random rank- observer is exactly
| (5.16) |
Moreover, for each singular direction ,
| (5.17) |
Proof.
By orthogonal invariance of the Haar measure on the Grassmannian, commutes with every orthogonal transformation of . Therefore for some scalar . Taking traces gives
| (5.18) |
so . Hence
| (5.19) |
Using the projector formula from Theorem 4.1,
| (5.20) |
Substituting gives
| (5.21) |
Dividing by yields the expected retained fraction. Finally, since
| (5.22) |
one has
| (5.23) |
∎
Proposition 5.3 gives the generic visibility benchmark in expectation. A random rank- observer retains a fraction on average. That number is purely geometric. It does not depend on the particular generator or the singular spectrum of . It is the baseline visibility of unstructured finite observation. No concentration or high-probability claim is being made here.
This baseline will be central for interpretation. If an actual observer performs only at the level, then it is no better than random geometry. If it performs substantially above that level, then it is aligned with the singular-energy front of the signal. If it performs substantially below the optimum, then there is room for observer redesign.
The literature has already encountered phenomena of this type indirectly. In coarse-graining and milestoning studies, some observation maps outperform others in ways that can seem paradoxical if one thinks only in terms of coarser versus finer observation [13]. The random-observer baseline clarifies the structural issue: generic observation has a fixed geometric retention level, and exceptional performance reflects alignment rather than raw resolution.
5.4 Alignment gain
The optimal retained fraction from Section 4 and the random-observer baseline from Theorem 5.3 together define the central quality measure of finite observation.
Definition 5.4 (Alignment gain).
Assume . For observable dimension , define the alignment gain
| (5.24) |
Equivalently,
| (5.25) |
Thus measures how much better the optimal rank- observer is than a generic rank- observer. It is the multiplicative benefit of observer design over random finite observation.
The first basic bounds are immediate.
Proposition 5.5 (Alignment-gain bounds).
Assume . Then for every observable dimension ,
| (5.26) |
In particular, the optimal observer always performs at least as well as the random baseline, and the maximal possible advantage is controlled by the inverse weighted complexity of the signal.
Proof.
For the lower bound, let
| (5.27) |
Then the average of the top terms is at least the average of all terms:
| (5.28) |
Rearranging gives
| (5.29) |
that is,
| (5.30) |
Hence .
Proposition 5.5 shows that alignment gain is a true quality measure. It is always at least one, because design can never be worse than random choice on average. It is large when the signal is concentrated and therefore strongly rewardable by alignment. It collapses toward one when the signal is diffuse and therefore little is gained by design over generic observation. A large post-cutoff singular-value gap therefore makes the optimal observer robust, while a flat spectrum pushes toward one and makes observer choice less consequential.
This gives another interpretation of weighted stable rank. A high stable-rank signal is not only difficult to see. It is also difficult to exploit by observer design. There is little alignment advantage available because the signal is spread broadly. A low stable-rank signal offers both strong visibility and large design gains.
It is also useful to record the rank-one case.
Corollary 5.6 (Rank-one alignment gain).
Assume . For ,
| (5.33) |
Thus the one-dimensional design gain is the ambient reduced dimension divided by the weighted stable rank of the signal.
Proof.
By Corollary 4.10,
| (5.34) |
Since the random baseline at rank one is , the claim follows immediately. ∎
Corollary 5.6 is especially sharp. It says that the whole one-mode design problem collapses to a single ratio: ambient reduced dimension divided by weighted stable rank.
5.5 Interpretation for the literature
The results of this section explain something that has remained somewhat implicit in the recent partial-observation literature. Many papers study finite resolution, hidden transitions, unresolved events, faulty coarse graining, or partial access, and ask why some observation schemes detect irreversibility better than others [5, 13, 6, 7, 8]. The usual language is framed in terms of better estimators, lower bounds, waiting-time information, or resolution trade-offs. Those are real and important. But they do not yet isolate the geometric core.
The theory says that the core issue is alignment with the weighted signal operator. A coarse-graining can outperform a finer observation if it is better aligned with the dominant left singular directions of . Conversely, increasing raw observational resolution may fail to help if the additional directions do not couple strongly to the singular front of the nonequilibrium signal. In that sense, the relevant distinction is not simply coarse versus fine. It is alignment versus misalignment.
This perspective also clarifies the meaning of generic observation. Absent design or structural knowledge, a rank- observer retains on average only the baseline fraction . Anything above that reflects nontrivial alignment. The gap between and is therefore not just a mathematical curiosity. It quantifies the advantage of informed observation over blind compression.
The section also changes the status of the finite observation programme itself. Up to this point, one could read the theory mainly as a structural suppression law. After the alignment theorem and the random-observer baseline, that is no longer adequate. The theory has become a design theory. It tells us not only what finite observers lose, but which finite observers are best, how much better they are than generic observers, and what geometric property of the signal makes that possible.
The next section introduces the shadow operator, which compares the visible nonequilibrium correction with the projected detailed-balance backbone and yields the Gaussian distinguishability theory.
6 The shadow operator and Gaussian distinguishability
6.1 Projected backbone and projected correction
Sections 3, 4, and 5 identified the weighted nonequilibrium signal, solved the rank-constrained visibility problem, and showed how observer quality is controlled by spectral alignment. What remains is to turn that visibility law into a statistical statement about what a finite observer can and cannot distinguish.
This is the point where the paper splits raw visibility from detectability. A direction can carry substantial visible nonequilibrium mass and yet be comparatively weak as a discriminator once the detailed-balance backbone is used as the local metric. Conversely, a direction that is not optimal for raw visible mass can become optimal after backbone normalisation. The observer enters this second problem twice: once through the projected nonequilibrium correction and once through the projected backbone. Raw visibility is therefore already measured in global detailed-balance units through the weighting, whereas detectability renormalises after projection in the local equilibrium units of the observed sector. The operator introduced below is the exact object that measures this second question.
Fix a rank- orthogonal projector on the reduced Euclidean Fisher space, and let
| (6.1) |
The observed detailed-balance backbone is the compression of to , while the observed nonequilibrium correction is the compression of to the same sector. Concretely, define
| (6.2) |
The observed Donsker-Varadhan Hessian is therefore
| (6.3) |
Since is positive definite on the full reduced space, its restriction to any nonzero subspace is positive definite. Thus is positive definite on . Since is positive semidefinite by Theorem 3.2, its compression is positive semidefinite on . The observed nonequilibrium law therefore differs from the observed detailed-balance law by a positive fluctuation correction on the same finite-dimensional observable sector.
This is the correct starting point for the equilibrium-shadow theorem. The question is not simply whether is small in an absolute sense. The real question is how large it is relative to the observed detailed-balance backbone . That relative object is introduced next.
6.2 The shadow operator
The observed nonequilibrium correction should be compared to the observed detailed-balance backbone in the natural backbone metric. This leads to the central operator of the section.
Definition 6.1 (Shadow operator).
The shadow operator associated with the observer is
| (6.4) |
The shadow operator is positive semidefinite on , and it is the observable measure of nonequilibrium fluctuation strength after normalising by the detailed-balance backbone. It is therefore the correct mathematical form of the equilibrium shadow.
Proposition 6.2 (Backbone factorisation).
For every rank- orthogonal projector ,
| (6.5) |
In particular, the observed nonequilibrium Hessian is a positive perturbation of the observed detailed-balance Hessian by the shadow operator.
Proof.
By definition,
| (6.6) |
Therefore
| (6.7) |
∎
Proposition 6.2 is the algebraic form of the shadow picture. The observed nonequilibrium fluctuation law is obtained from the observed detailed-balance backbone by inserting the positive dimensionless perturbation .
We next connect this to Gaussian fluctuation laws.
6.3 Exact observed Gaussian laws
Throughout Sections 6 and 8, the observed Gaussian law on means the centred Gaussian law induced by the compressed quadratic fluctuation form on , with precision in the detailed-balance case and in the nonequilibrium case. This is the local compressed-Hessian observation model fixed by the paper. It is not, unless explicitly stated otherwise, a theorem about arbitrary nonlinear measurement marginals or full path-space observations.
At the quadratic fluctuation level, the observed detailed-balance and observed nonequilibrium laws on are centred Gaussian measures with precisions
| (6.8) |
Their covariance operators are therefore
| (6.9) |
Using Proposition 6.2, the nonequilibrium covariance can be written as
| (6.10) |
Thus every Gaussian distinguishability quantity on the observed sector is a spectral function of the shadow operator. This is the decisive statistical simplification. The observed detailed-balance backbone has been factored out completely, and the remaining difference between the two observable Gaussian laws is encoded entirely by .
We now write the principal divergences explicitly. Throughout, total variation is defined by
| (6.11) |
and the squared Hellinger distance is defined by
| (6.12) |
for any common dominating measure .
Theorem 6.3 (Exact Gaussian comparison formulas).
Let be the eigenvalues of . Then the reverse Kullback-Leibler divergence is
| (6.13) |
and the forward Kullback-Leibler divergence is
| (6.14) |
Moreover, the squared Hellinger distance is
| (6.15) |
These formulas are observable Gaussian comparison laws. They are naturally adjacent to trajectory-level time-reversal Kullback–Leibler comparisons in the style of Roldán–Parrondo, but they are not the same object [36].
Proof.
For centred Gaussian laws with covariances ,
| (6.16) |
Take and . Then
| (6.17) |
so its eigenvalues are . Hence
| (6.18) |
which simplifies to the first formula.
For the forward divergence, take and . Then
| (6.19) |
whose eigenvalues are . Substituting into the Gaussian KL formula yields
| (6.20) |
since
| (6.21) |
This is the stated expression.
For the Hellinger distance, the standard centred-Gaussian formula gives
| (6.22) |
Using
| (6.23) |
one computes
| (6.24) |
and
| (6.25) |
Therefore
| (6.26) |
so the common -factor cancels and one obtains
| (6.27) |
This gives the claimed expression. ∎
Theorem 6.3 is the precise statistical content of the shadow construction. Every local centred-Gaussian distinguishability quantity between the observed detailed-balance law and the observed nonequilibrium law is an explicit function of the eigenvalues of .
Proposition 6.4 (Shadow spectrum as complete Gaussian control object).
For a fixed observer , the observed Gaussian pair
| (6.28) |
is equivalent, under invertible linear whitening and orthogonal diagonalisation, to the product pair
| (6.29) |
where are the eigenvalues of . Consequently, every invertibly invariant centred-Gaussian discrimination functional of the observed pair is determined by the shadow spectrum alone.
Proof.
Whiten by the detailed-balance covariance and diagonalise . The relation
| (6.30) |
shows that, after whitening by , the observed pair becomes
| (6.31) |
Orthogonal diagonalisation of then yields the displayed product form. Any centred-Gaussian discrimination functional invariant under invertible changes of coordinates is preserved by these steps, so it depends only on the eigenvalues of . ∎
This complements the current literature on partial observation, which largely provides lower bounds, estimators, or observation-dependent thermodynamic laws [5, 13, 6, 7, 19, 8]. Here the local Gaussian visibility problem in the compressed-Hessian model is resolved in finite-dimensional form once the DV signal is written in the appropriate weighted coordinates.
6.4 Distinguishability package
The formulas of Theorem 6.3 immediately imply a collection of sharp and simple bounds. These are the estimates that turn the shadow operator into a practical observable criterion.
Proposition 6.5 (KL and total-variation bounds).
For every observer ,
| (6.32) |
Consequently,
| (6.33) |
For equal priors, the optimal Bayes classification error satisfies
| (6.34) |
Proof.
Consider the scalar function
| (6.35) |
Then
| (6.36) |
and . Hence , or equivalently,
| (6.37) |
Applying this estimate termwise in Theorem 6.3 gives
| (6.38) |
Pinsker’s inequality then yields
| (6.39) |
For equal priors, the optimal Bayes error satisfies
| (6.40) |
so the total-variation bound gives the stated lower bound. ∎
Proposition 6.5 shows that the shadow operator is not just a formal factorisation device. Its Frobenius norm directly controls statistical distinguishability at the Gaussian level.
We next bound the shadow operator in terms of the visible envelope and the observed backbone scale.
Proposition 6.6 (Backbone-normalised visibility bound).
For every observer ,
| (6.41) |
In particular,
| (6.42) |
Proof.
Since ,
| (6.43) |
Because is positive semidefinite,
| (6.44) |
Thus
| (6.45) |
Similarly,
| (6.46) |
Again , hence
| (6.47) |
which gives
| (6.48) |
Since , the final bounds follow. ∎
Proposition 6.6 is the missing link between the finite-observation envelope and the statistical shadow criterion. The visible envelope by itself is not enough to guarantee indistinguishability. What matters is the visible envelope relative to the observed detailed-balance backbone.
The correction is visible only through the ratio
| (6.49) |
This is the backbone-normalised observation budget. It is the quantity that turns retained signal into statistical closeness. This criterion is observer-specific unless one also imposes a uniform lower bound on .
6.5 The equilibrium shadow criterion
We can now progress to the paper’s main statistical theorem in its final form.
Theorem 6.7 (Gaussian equilibrium-shadow criterion).
Let be a rank- observer and let be its shadow operator. Then the observed nonequilibrium and observed detailed-balance Gaussian laws are exactly identical if and only if .
More generally, if
| (6.50) |
then
| (6.51) |
| (6.52) |
and
| (6.53) |
If
| (6.54) |
for some , then the compressed Gaussian fluctuation law is quantitatively close to the corresponding detailed-balance Gaussian fluctuation law, with bounds given above in terms of . This is a statement about observed quadratic-Gaussian statistics, not about the full microscopic dynamics.
Proof.
The identification follows from Proposition 6.2. Since is positive definite,
| (6.55) |
Now assume . Since , all eigenvalues satisfy . From Theorem 6.3,
| (6.56) |
Using , we obtain
| (6.57) |
Pinsker then gives
| (6.58) |
The Bayes error bound follows as in Proposition 6.5.
Finally, Proposition 6.6 yields
| (6.59) |
Thus small backbone-normalised visible envelope implies small , and hence small divergence and small total variation. ∎
Theorem 6.7 is the rigorous form of the equilibrium-shadow principle. Within the compressed quadratic-Gaussian regime, finite orthogonal observation can erase visible nonequilibrium detail and leave only an equilibrium-shaped backbone. The theorem makes that precise.
There are two ingredients. Firstly, the visible nonequilibrium budget, controlled by the envelope . The second is the observed backbone stiffness, controlled by . The shadow criterion says that equilibrium-shaped observation emerges when the visible nonequilibrium budget is small relative to the stiffness of the observed detailed-balance backbone.
This corrects a point that would otherwise remain too loose. The inequality
| (6.60) |
controls how much of the total nonequilibrium signal can be retained. It does not by itself imply statistical indistinguishability from detailed balance. The shadow theorem identifies the missing ingredient, namely the backbone scale.
6.6 Backbone-whitened detectability geometry
The shadow criterion identifies the correct backbone-normalised observable quantity, but it also admits a second spectral reformulation. Define the backbone-whitened operator
| (6.61) |
This operator encodes detectability relative to the detailed-balance backbone rather than raw visible signal. In general its spectral order need not coincide with the spectral order of , except in commuting or isotropic-backbone regimes treated later.
Theorem 6.8 (Backbone-whitened detectability equivalence).
Let be a -dimensional observable subspace, and let have orthonormal columns spanning . Define
| (6.62) |
and
| (6.63) |
Then
| (6.64) |
Hence
| (6.65) |
where and is the Euclidean orthogonal projector onto . Conversely, every Euclidean -plane arises as for a unique observable -plane .
Proof.
Direct computation gives
| (6.66) |
and
| (6.67) |
For the converse, let be any Euclidean -plane and let have orthonormal columns spanning . Set , and define
| (6.68) |
Then , so is an observable -plane. Moreover,
| (6.69) |
so indeed . ∎
Remark (Detectability versus raw visibility).
Theorem 6.8 is a bijection between observable -planes and whitened Euclidean -planes. It is not a statement about arbitrary observation channels. Detectability here is defined relative to -normalised quadratic compression and should not be conflated with raw visible signal unless additional commuting or isotropic-backbone structure is imposed.
Theorem 6.8 shows that the backbone-normalised detectability problem is itself a Ky Fan problem, now for the whitened signal rather than the raw visible signal .
Corollary 6.9 (Exact detectability envelope).
Let
| (6.70) |
be the eigenvalues of , equivalently
| (6.71) |
Define
| (6.72) |
Then
| (6.73) |
The maximiser is the observable subspace whose whitened image is the span of the top eigendirections of .
If
| (6.74) |
then
| (6.75) |
Proof.
By Theorem 6.8, every observable -plane induces a Euclidean compression of . The statement is therefore exactly the Ky Fan maximum principle for the positive semidefinite matrix , together with the complement argument for the minimum and the usual stable-rank bound. ∎
The operator is not an arbitrary positive semidefinite matrix. Because it is generated by the whitened skew carrier , its positive spectrum is forced to organise into orthogonal current planes. The next proposition records this intrinsic structure and the detectability consequences needed later.
Proposition 6.10 (Canonical current-plane decomposition).
There exist pairwise orthogonal two-dimensional subspaces
| (6.76) |
positive numbers
| (6.77) |
and an orthogonal decomposition
| (6.78) |
such that for each ,
| (6.79) |
and therefore
| (6.80) |
Proof.
Since
| (6.81) |
the operators and commute. Decompose into orthogonal eigenspaces of :
| (6.82) |
Each is therefore -invariant. On with ,
| (6.83) |
Hence
| (6.84) |
satisfies
| (6.85) |
Thus is orthogonal and skew. If is a unit vector and , then
| (6.86) |
so is an invariant two-plane on which . Repeating this construction yields an orthogonal decomposition of each positive eigenspace into invariant two-planes. Finally,
| (6.87) |
so . ∎
Corollary 6.11 (Paired detectability spectrum).
Let
| (6.88) |
be the eigenvalues of . Then every positive detectability eigenvalue has even multiplicity. More precisely,
| (6.89) |
and all remaining eigenvalues are zero. Consequently,
| (6.90) |
so the nonequilibrium correction can never have rank one.
Proof.
This is immediate from Proposition 6.10 and the identity . ∎
Corollary 6.12 (Universal rank-one detectability ceiling).
Assume , so that the retained fractions from Corollary 6.9 are defined. Then
| (6.91) |
Equality holds if and only if , equivalently if and only if there is exactly one nonzero current plane.
Proof.
The backbone-whitened detectability spectrum is therefore constrained by skew-current geometry rather than being an arbitrary positive spectrum. In particular, the one-dimensional ceiling in the detectability problem is structural rather than model-specific.
Corollary 6.13 (Generalised eigenvalue formulation of detectability).
The nonzero eigenvalues of are the generalised eigenvalues of the pair :
| (6.94) |
The optimal detectable modes may be chosen as -orthonormal generalised eigenvectors
| (6.95) |
and
| (6.96) |
Proof.
If , then setting gives the generalised eigenvalue relation . Conversely, any generalised eigenvector yields a whitened eigenvector of with the same eigenvalue. The envelope identity follows from Corollary 6.9. ∎
Corollary 6.14 (Detectability spectroscopy).
The cumulative detectability envelope recovers the detectability spectrum:
| (6.97) |
Hence the full backbone-normalised detectability spectrum is encoded by the hierarchy .
Proof.
Immediate from
| (6.98) |
∎
Corollary 6.15 (Rank-one detectability and the top generalised eigenmode).
The optimal one-dimensional detectable observer solves
| (6.99) |
Equivalently, is the top generalised eigenvalue of the pair , or the top eigenvalue of . Thus
| (6.100) |
The optimal one-mode detectable direction is any -normalised generalised eigenvector satisfying
| (6.101) |
Proof.
This is the rank-one case of Corollary 6.9 and the Rayleigh–Ritz characterisation of the top generalised eigenvalue. ∎
Theorem 6.16 (Two-envelope backbone spectroscopy).
Assume
| (6.102) |
and let
| (6.103) |
Let
| (6.104) |
be the eigenvalues of , and let
| (6.105) |
be the eigenvalues of . If
| (6.106) |
then for every ,
| (6.107) |
Consequently, for every ,
| (6.108) |
Proof.
The numbers are the generalised eigenvalues of the pair , equivalently the eigenvalues of . By the Courant–Fischer principle,
| (6.109) |
Since
| (6.110) |
one has
| (6.111) |
Applying the Courant–Fischer principle again to yields
| (6.112) |
Summing from to gives the envelope bounds. ∎
Proposition 6.17 (Exact commuting-case backbone spectroscopy).
Assume
| (6.113) |
Then there exists an orthogonal basis in which
| (6.114) |
with and . In that basis,
| (6.115) |
Hence along each common eigenvector the corresponding generalised eigenvalue is the ratio . Equivalently, the spectrum of is the multiset of ratios , with common eigenvectors of and furnishing the modes.
Proof.
Real symmetric commuting matrices are simultaneously orthogonally diagonalisable. The displayed formula for is then immediate. ∎
Corollary 6.18 (Isotropic-backbone reduction).
If is isotropic on , meaning
| (6.116) |
then
| (6.117) |
Hence raw visibility and detectability choose the same eigendirections, and their spectra differ only by the constant factor .
Theorem 6.16 gives the generic spectral-window sandwich between raw visibility and detectability, while Proposition 6.17 gives the exact commuting sharpened case. This commuting regime isolates the effect of the detailed-balance backbone: detectability is raw visibility reweighted by directional backbone penalties. It is therefore natural to speak of backbone friction when describing the difference between the raw signal spectrum and the detectability spectrum.
Corollary 6.19 (Raw-to-detectability discrimination bounds via the backbone window).
Let be an optimal detectable -plane from Corollary 6.9, so that the shadow spectrum of is . Then
| (6.118) |
| (6.119) |
and
| (6.120) |
If additionally , then
| (6.121) |
| (6.122) |
and
| (6.123) |
Consequently,
| (6.124) |
so the backbone window transfers raw visibility bounds directly into total-variation and Bayes-error bounds.
Proof.
The exact formulas are Theorem 6.3 applied to the optimal detectable observer , whose shadow spectrum is by Corollary 6.9. The eigenvalue bounds come from Theorem 6.16. The scalar functions
| (6.125) |
are increasing on , while
| (6.126) |
is decreasing on . Substituting the eigenvalue sandwich into the exact formulas yields the displayed bounds, and the total-variation and Bayes relations are standard. ∎
6.7 Noisy Gaussian observation extension
The deterministic-subspace theory solved in the main text extends at the Gaussian level to fixed linear noisy observation channels, although the resulting optimisation problem is no longer a Ky Fan problem. The deterministic projector model is recovered as the sharp-channel limit of this Gaussian observation setting.
Theorem 6.20 (Exact Gaussian noisy-channel shadow formulas).
Let the latent detailed-balance and NESS Gaussian fluctuation laws be
| (6.127) |
with
| (6.128) |
Let the observer act through a linear Gaussian channel
| (6.129) |
where and . Then
| (6.130) |
with
| (6.131) |
Define the latent covariance defect
| (6.132) |
and the observed covariance defect
| (6.133) |
Define the noisy-channel shadow operator
| (6.134) |
Then
| (6.135) |
If are the eigenvalues of , then
| (6.136) |
and
| (6.137) |
Proof.
The covariance factorisation is immediate from
| (6.138) |
The KL formulas follow from the standard centred-Gaussian divergence formula applied to
| (6.139) |
∎
No optimisation claim over and is included here. The theorem gives Gaussian comparison formulas for a fixed linear Gaussian observation channel. The bounded interval is the natural noisy analogue of the unbounded shadow spectrum: added observation noise forces the observed defect to remain strictly below the noisy baseline covariance.
6.8 Physical interpretation
Section 6 completes the passage from weighted signal geometry to observable statistics.
The shadow operator is the central object. It measures the visible nonequilibrium correction in the correct backbone metric. Large shadow means the observed nonequilibrium Gaussian law is visibly different from the observed detailed-balance Gaussian law. Small shadow means the observed law is close to the detailed-balance backbone even when the full system is strongly nonequilibrium microscopically.
This is the precise sense in which finite observation can hide irreversibility in the compressed quadratic-Gaussian regime. The hiding is not a metaphor. It is a spectral statement, and after backbone whitening it is governed by a second spectrum. The fixed-channel noisy extension above shows that the same Gaussian comparison structure survives beyond deterministic subspace observation, although the corresponding channel-design problem is open.
At this point the classical theorem package is now in place. The nonequilibrium correction is a weighted signal. Its visible share under rank constraint is computable. Observer quality is an alignment problem. Detectability is controlled by a second, backbone-whitened spectrum. Statistical indistinguishability from detailed balance is governed by the shadow operator. The next section shows that the envelope hierarchy also gives spectral readout of the hidden nonequilibrium structure.
7 Spectroscopy and the anatomy of hidden nonequilibrium structure
7.1 The cumulative envelope as a spectral readout
Up to this point, the observable envelope
| (7.1) |
has been interpreted as the optimal retained signal at observable dimension . That interpretation is already strong, but it is not yet the full story.
The envelope is a cumulative spectral readout of the weighted nonequilibrium signal. Once the bridge identity has identified
| (7.2) |
the sequence
| (7.3) |
contains the cumulative singular-energy content of mode by mode. The visible nonequilibrium signal retained by the best rank- observer is therefore the -mode cumulative spectrum of the signal.
This changes the status of the theory. Finite observation is not only a statement about what is lost under compression. The envelope hierarchy is also a diagnostic object: it reveals the spectral anatomy of what is hidden.
To make that precise, set
| (7.4) |
The next theorem shows that the envelope increments recover the singular-energy profile.
Theorem 7.1 (Cumulative envelope and ordered spectral increments).
For each ,
| (7.5) |
Equivalently, the ordered singular-energy profile of the weighted nonequilibrium signal is obtained by discrete differentiation of the envelope hierarchy.
Proof.
Theorem 7.1 is the decisive spectral statement of the paper. The observable envelope is an cumulative readout of the ordered singular-energy spectrum of the hidden nonequilibrium signal.
This is why the phrase “spectroscopy of nonequilibrium visibility” is not just rhetorical. The envelope hierarchy is a spectral measurement object. If one knows the full sequence , one knows the ordered singular-energy profile of the weighted signal.
7.2 Recovery of the singular-energy spectrum
The preceding theorem gives an immediate recovery result.
Corollary 7.2 (Recovery of the ordered singular-energy profile).
For each ,
| (7.8) |
Hence the full ordered singular-energy spectrum of is determined exactly by the envelope hierarchy.
Proof.
Multiply the identity of Theorem 7.1 by . ∎
Corollary 7.2 is one of the strongest hidden consequences of the finite-observation programme. The envelope hierarchy contains complete information about the ordered weighted singular spectrum of the DV signal. In particular, the envelope is not only enough to state retention and hidden-fraction theorems. It is enough to reconstruct the ordered spectral anatomy of the signal.
This gives the theory a genuinely diagnostic character. A retained-signal curve indexed by observable dimension is often thought of as a cumulative performance measure. Here it is much more. It is a complete cumulative encoding of the signal spectrum itself. What it does not recover is the singular-direction frame, still less the microscopic generator.
It is convenient to record the equivalent statement directly at the level of the positive signal operator .
Corollary 7.3 (Recovery of the nonzero spectrum of the DV correction).
The nonzero eigenvalues of are
| (7.9) |
and are recovered from the envelope increments:
| (7.10) |
Proof.
Corollary 7.3 shows that the envelope hierarchy may equally well be read as the cumulative eigenvalue profile of the positive signal operator . The signal can therefore be viewed either at the singular-value level through or at the eigenvalue level through . The two viewpoints are equivalent.
7.3 Complexity measures from the envelope
Once the envelope hierarchy is known, several structural invariants of the nonequilibrium signal become immediately accessible. The first is the total signal strength:
| (7.12) |
The second is the top singular energy:
| (7.13) |
Together these determine the weighted stable rank.
Corollary 7.4 (Recovery of weighted stable rank).
If , then
| (7.14) |
Proof.
By definition,
| (7.15) |
while
| (7.16) |
Therefore
| (7.17) |
∎
The weighted stable rank was introduced in Definition 4.6 of Section 4 as the effective dimensionality of the nonequilibrium signal. Corollary 7.4 shows that it is also an envelope observable. It is not an auxiliary definition imposed from outside. It is already encoded in the retention hierarchy.
The envelope also determines the signal rank.
Corollary 7.5 (Recovery of signal rank).
The rank of the weighted signal operator is the number of strictly positive envelope increments:
| (7.18) |
Equivalently,
| (7.19) |
Proof.
By Corollary 7.2,
| (7.20) |
The number of positive singular values is the rank of . Since , the ranks coincide. ∎
More generally, every unitarily invariant spectral quantity of , and every spectral quantity of , is determined by the envelope sequence. This includes Schatten norms, nuclear norm, operator norm, Frobenius norm, spectral entropy, and any other symmetric functional of the singular-energy profile.
Proposition 7.6 (Spectral completeness of the envelope).
The sequence determines the full singular-value list of , and hence determines every spectral functional of and every spectral functional of .
Proof.
Corollary 7.2 recovers every singular value squared from the successive envelope increments. Any spectral functional is a symmetric function of the singular values, so it is determined by the recovered list. Since has nonzero spectrum , its spectral functionals are also determined. ∎
Proposition 7.6 is the most compact way to state the diagnostic strength of the theory. The envelope hierarchy determines the eigenvalue profile of , equivalently the singular-energy profile .
7.4 Observability order between systems
The envelope hierarchy now suggests a natural way to compare nonequilibrium systems by finite-observation visibility.
Let and be two finite-dimensional irreducible Markov nonequilibrium generators, with corresponding weighted signal operators and , and envelope hierarchies and . When the reduced dimensions differ, the shorter singular-energy list is understood to be zero-padded before comparison, so the quantifier "for every " is unambiguous.
Definition 7.7 (Observability dominance).
We say that dominates in the strong observability order if
| (7.21) |
We say that dominates in the normalised observability order if
| (7.22) |
The strong order compares absolute visible signal budgets. The normalised order compares how concentrated the signal is independently of overall scale.
The next proposition identifies the underlying spectral meaning of these two orders.
Proposition 7.8 (Spectral meaning of observability dominance).
The following are equivalent:
-
1.
dominates in the strong observability order,
-
2.
for every ,
(7.23)
In particular, strong observability dominance is weak majorisation of the squared singular-value vectors, equivalently dominance of the Ky Fan partial sums.
Similarly, if the total signals agree,
| (7.24) |
then normalised observability dominance is equivalent to majorisation of the normalised singular-energy profiles.
Proof.
The strong statement is immediate from the definition of the envelope:
| (7.25) |
The factor is common to both systems and therefore irrelevant to the order.
For the normalised statement, divide both envelope hierarchies by the common total signal. The resulting cumulative fractions are the retention fractions . ∎
Proposition 7.8 gives a clean comparative language that the existing literature lacks. Two systems can have the same overall nonequilibrium strength but very different visibility profiles under finite observation. One may be more observable at every observational budget because its signal is more concentrated in the leading modes. The other may be thermodynamically active but spectrally diffuse and therefore harder to access.
This is a central consequence of the theory. The finite-observation programme ranks systems not only by how much nonequilibrium they contain, but by how that nonequilibrium is distributed across observable directions.
7.5 Practical meaning
Section 7 changes the status of the envelope hierarchy in three ways.
First, it shows that the envelope is the cumulative spectral profile of the weighted nonequilibrium signal. The paper is therefore not only about how much finite observers miss, but about the spectral anatomy of what they miss.
Second, it shows that weighted stable rank is not simply a convenient scalar bound. It is an envelope-derived complexity invariant. The same retention hierarchy that determines the optimal visible fraction also determines the effective dimensionality of the signal. The theory is therefore internally closed: the object that controls visibility is extracted from the same spectral data that governs retention.
Third, it provides a new comparative language for nonequilibrium systems. Systems can now be compared by observability profile, not just by total dissipation or total correction size. A system with a highly concentrated signal may be easy to diagnose under severe observational constraints, while a system with a diffuse signal may remain effectively hidden even if its total nonequilibrium strength is large.
It reveals the diagnostic content of the theory. The envelope hierarchy is a spectroscopy of hidden nonequilibrium structure. The backbone-whitened detectability operator reveals a second spectrum, governing observer design against the detailed-balance backbone. Noisy observation channels admit a Gaussian shadow extension, even though the optimal channel-design problem remains open.
That shift has real consequences for the rest of the paper. Suppression and classification under structural assumptions, rank-constrained retention mechanisms, and the weighted signal operator are all now unified in one argument. Section 7 shows that once these ingredients are combined, one gets a cumulative spectral theory of finite nonequilibrium visibility.
The next section uses this spectral viewpoint to reinterpret suppression and shared observed-Gaussian behaviour under structural assumptions as corollaries of the deeper signal theory. That is where the classical part of the paper closes.
8 Projection suppression and shared observed-Gaussian behaviour as corollaries
8.1 Projection suppression revisited
The preceding sections show that the finite-observation problem is governed by two objects: the visible envelope , which controls how much of the nonequilibrium correction can survive rank- observation, and the shadow operator , which compares that visible correction to the projected detailed-balance backbone. This recasts structural projection suppression in a cleaner and more structural way.
A suppression theorem can be established under an explicit family of structural assumptions on the slow and fast sectors, together with a classification of observable normal forms once the projected nonequilibrium correction becomes asymptotically negligible. The key point of the work is that those assumptions are no longer the primitive centre of the theory. They are one sufficient route to a more basic conclusion.
The new primitive statement is this: if the visible envelope is small relative to the observed detailed-balance backbone, then the observed nonequilibrium Gaussian law is close to the observed detailed-balance law. In the notation of Section 6, suppression means that
| (8.1) |
is small. Everything else is a mechanism for forcing this ratio to be small.
It is therefore useful to state the relationship to the structural suppression result explicitly.
Corollary 8.1 (Gaussian projection suppression criterion).
Let be a rank- observable projector. Suppose that a family of generators satisfies
| (8.2) |
Then the compressed Gaussian fluctuation laws converge, in Kullback-Leibler divergence, total variation, and Hellinger distance, to the corresponding compressed detailed-balance Gaussian laws. In particular, the projected Donsker-Varadhan Hessian becomes asymptotically indistinguishable from the projected detailed-balance backbone at the observed Gaussian level.
Proof.
Corollary 8.1 is the precise way in which the structural suppression result is absorbed. The suppression result does not disappear. It is strengthened and reinterpreted. A structural list of hypotheses is now seen as one way of forcing a simpler and more primitive visible-envelope ratio to be small.
8.2 The role of the structural assumptions
A suppression analysis based on five structural assumptions governing the slow-fast geometry of the generator proves asymptotic suppression of the projected nonequilibrium correction. From this viewpoint, those assumptions should be read as engineering conditions that drive the backbone-normalised visible envelope to zero.
This is clearest at the block level. By Theorem 3.5, the observed nonequilibrium correction admits, relative to the chosen -adapted block decomposition, an intrinsic slow contribution and a hidden-return contribution from the complementary sector. The structural assumptions act on these two blocks in precisely the way now suggested by the finite-observation theory.
First, conditions enforcing small slow-skew action reduce the intrinsic slow contribution. Second, conditions forcing delocalisation or decay of the mixed channel reduce the hidden return contribution. Third, fast-block coercivity penalises any remaining hidden return by weighting it against a stiff fast detailed-balance backbone. Together, these mechanisms drive the visible correction downward.
These assumptions are therefore not arbitrary. They are sufficient conditions for keeping the visible nonequilibrium signal small in comparison with the observed detailed-balance backbone. From this viewpoint, they do not define the suppression phenomenon. They instantiate it.
This reinterpretation is important because it changes the logical status of the suppression result. In a purely structural formulation, the assumptions must be stated as primitive hypotheses because the signal form of the nonequilibrium correction is not yet available. Once the bridge is closed and the weighted envelope is known, the assumptions take their proper place as family-level mechanisms forcing the basic spectral ratio to be small.
One can therefore summarise the relationship as follows:
The structural suppression theorem says that certain slow-fast hypotheses imply projection suppression.
The present theory says that projection suppression occurs whenever the visible envelope is small relative to the observed backbone, and that those hypotheses are one way of ensuring exactly that.
That is a genuine simplification. It compresses a list of family-dependent conditions into a single visibility criterion with geometric and statistical meaning.
8.3 Shared observed-Gaussian behaviour
Once the projected nonequilibrium correction becomes negligible, observable behaviour collapses to the projected normal form . We now reveal why that collapse occurs.
The reason is spectral. The nonequilibrium correction is a positive weighted correction operator. Finite observation can only retain the singular-energy front of that signal. When the visible envelope is small relative to the observed backbone, the observer sees only the projected metric and projected generator sectors to leading order. The finer nonequilibrium structure may persist microscopically, but it is spectrally invisible in the observed Gaussian law.
This yields the following shared-normal-form statement.
Corollary 8.2 (Asymptotic shared observed-Gaussian behaviour under a common projected normal form).
Fix an observable rank . Let and be two families of finite-dimensional irreducible Markov generators with the same projected normal form for each :
| (8.4) |
Let denote the common projected detailed-balance backbone determined by that shared normal form, and suppose that for ,
| (8.5) |
Then each observed Gaussian fluctuation law converges, in Kullback-Leibler divergence, total variation, and Hellinger distance, to the common projected detailed-balance Gaussian law determined by . Consequently, the two observed Gaussian laws converge to one another in total variation and Hellinger distance.
In particular, the observed Gaussian equivalence class is governed asymptotically by the projected normal form once the visible nonequilibrium correction becomes negligible relative to the projected backbone.
Proof.
Since the projected normal forms coincide, the projected detailed-balance backbones agree and are equal to . For each family, Corollary 8.1 implies convergence of the observed nonequilibrium Gaussian law to the common detailed-balance Gaussian law because
| (8.6) |
The pairwise total-variation and Hellinger conclusions then follow from the triangle inequality for those distances. We do not invoke a triangle inequality for Kullback-Leibler divergence. ∎
Corollary 8.2 gives the final version of this shared-normal-form idea. Different generators can collapse onto the same observed Gaussian class once the projected correction is suppressed relative to the projected backbone. The paper explains the mechanism: finite observation removes most of the weighted nonequilibrium signal, and once the visible remainder is small compared with the backbone, only the projected normal form survives statistically.
In this sense, the shared behaviour is asymptotic and Gaussian. It is a consequence of a spectral bottleneck on nonequilibrium visibility.
8.4 Internal hierarchy of observational equivalence
The internal hierarchy of projected observables now sits naturally inside the final theorem package. It is useful to restate it compactly.
At the coarsest level there is static equivalence: two systems agree on the observed metric structure of the accessible sector. This is the level of and .
At the next level there is dissipative equivalence: two systems share the same projected dissipative backbone , and therefore the same observed detailed-balance Hessian .
At the finest level there is projected normal-form equivalence: two systems share the same projected triple , and therefore the same observable linear normal form in the absence of visible nonequilibrium correction.
The theory inserts one more statement into this hierarchy. The shadow operator tells us when the observed nonequilibrium correction is too small to disturb this projected hierarchy at the observed Gaussian level. Thus the hierarchy is now:
-
1.
static observable structure,
-
2.
projected dissipative backbone,
-
3.
projected normal form,
-
4.
projected nonequilibrium shadow.
The classification theorem can now be read as saying that once the fourth layer is spectrally negligible, the first three determine the observed class completely.
This is a substantial conceptual improvement over an isolated taxonomy of projected data. The hierarchy is no longer just a nested classification of projected observables. It is the hierarchy of what survives once finite observation has truncated the weighted nonequilibrium signal.
8.5 Parameter compression
The full observable normal form on a rank- sector is determined by a finite parameter count, leading to a strong compression of the observable description. That compression result also has a more structural meaning.
The visible nonequilibrium correction is not an arbitrary additional object of the same formal size as the backbone. It is a weighted signal that finite observation can only access through a rank-constrained singular-energy front. Once that visible front is negligible relative to the projected backbone, the observer is left with the projected normal form alone, with its already-known compressed parameter count.
Thus the parameter compression theorem can now be read as the endpoint of a two-step reduction:
-
1.
the weighted nonequilibrium signal is spectrally thinned by finite observation,
-
2.
the remaining observable law collapses onto the projected normal form with its finite parameter budget.
That is the sharper conceptual picture. The finite parameter count is not just a convenient descriptive simplification. It is what is left after the visible nonequilibrium sector has been spectrally exhausted.
9 Abstract weighted geometry and operator-space transfer
9.1 Abstract metric setting
The classical theory developed so far lives on the reduced Euclidean Fisher space, where the detailed-balance Hessian has already been used to whiten the nonequilibrium correction into the signal operator . The next step is to recognise that the linear algebra of visible envelopes, retention fractions, and stable-rank control is not inherently classical. It belongs to a more general weighted Hilbert-space framework.
Let be a finite-dimensional real or complex vector space equipped with a positive-definite metric operator , so that
| (9.1) |
defines an inner product. We denote the corresponding norm by . An operator on is called -orthogonal if it is idempotent and self-adjoint with respect to . Equivalently,
| (9.2) |
where is the -adjoint.
Suppose now that a positive semidefinite correction operator on is represented in the weighted geometry through a symmetrised signal factorisation
| (9.3) |
for some operator . This is the abstract analogue of the classical identity
| (9.4) |
on the reduced Euclidean Fisher space.
The key observation is that the visible-envelope theory depends only on this weighted signal factorisation and the geometry of -orthogonal compression. Once the metric is Euclideanised, the whole classical Ky Fan theory transfers directly.
9.2 Weighted envelopes and retention in the abstract setting
Let be an -orthogonal projector of rank . The natural visible signal retained by is
| (9.5) |
where the trace is the algebraic trace on the finite-dimensional space and the Euclideanisation is used only to express the projected Frobenius energy. Because , this quantity admits the same projected-energy interpretation as in the classical case.
To state the transfer theorem cleanly, choose the positive-definite self-adjoint square root , and define the Euclideanised signal operator
| (9.6) |
Likewise, if is -orthogonal, define its Euclideanised projector
| (9.7) |
Then is an ordinary Euclidean orthogonal projector of the same rank, and the visible signal may be computed entirely in Euclidean form. Because is positive definite, this similarity map is invertible and preserves rank, so rank- -orthogonal observers correspond exactly to rank- Euclidean orthogonal projectors. This is the content of the operator-space transfer theorem proved in this section.
Theorem 9.1 (Abstract weighted envelope theorem).
Let be a finite-dimensional metric space with positive-definite metric , and let be a positive semidefinite correction operator on . Define
| (9.8) |
Then for every -orthogonal projector ,
| (9.9) |
Consequently, the optimal rank- visible signal is given by the Ky Fan top-singular-energy envelope of , the retention fraction is the corresponding cumulative singular-energy ratio, and the effective complexity invariant is the stable rank of .
Proof.
Conjugation by sends -orthogonal projectors to Euclidean orthogonal projectors. Moreover,
| (9.10) |
so the weighted signal factorisation becomes an ordinary Euclidean Gram form. Therefore
| (9.11) |
and the Euclidean projector formula, Ky Fan envelope theorem, retention hierarchy, and stable-rank obstruction apply verbatim. ∎
Proposition 9.2 (Factorisation-gauge invariance).
Suppose with for an -unitary operator satisfying . Then the visible signal, envelope hierarchy, retention fractions, stable rank, and ordered singular-energy profile obtained after Euclideanisation are identical for and .
Proof.
Euclideanisation sends to an ordinary unitary factor on the right of . Right multiplication by a unitary does not change singular values, and all stated quantities depend only on those singular values. ∎
This shows that the visibility spectrum depends only on the correction operator itself, not on the particular square-root factor used to represent its Gram structure.
The content of Theorem 9.1 is not merely a change of coordinates: Euclideanisation preserves the rank-constrained trace objective and transports the Gram correction into ordinary Euclidean form, so the weighted visibility problem becomes exactly a Ky Fan singular-value problem.
Theorem 9.1 is important for two reasons. First, it shows that the visible-envelope machinery is not a curiosity of the classical Fisher reduction. It is a theorem of weighted signal geometry. Second, it makes the quantum continuation of the paper almost automatic at the level of weighted-geometry transfer. Once the physically relevant quantum correction object is identified in a BKM-type metric geometry, the same envelope and retention theory follows by Euclideanisation.
9.3 Classical Fisher geometry as a special case
The finite-dimensional Markov theory developed in Sections 2 to 8 is the first special case of the abstract metric framework.
Indeed, after passing to the reduced Euclidean Fisher coordinates and whitening by the detailed-balance Hessian, the correction takes the ordinary Gram form
| (9.12) |
This is a special case of the abstract factorisation , with the metric already Euclideanised and the signal operator chosen as
| (9.13) |
so that .
Thus every theorem of the earlier sections can be re-read as an instance of the abstract weighted geometry theorem, specialised to the finite-dimensional Markov nonequilibrium setting. The classical results are therefore not separate from the theory. They are its first concrete realisation.
This point clarifies what is fundamental in the earlier sections. The bridge theorem is classical and model-specific because it identifies the signal operator . Once that signal is identified, the visible-envelope, retention, alignment, and spectroscopy machinery is generic weighted linear algebra.
9.4 BKM operator geometry as a special case
The second special case is the BKM-symmetrised operator geometry. There the role of the ambient metric is played by the Bogoliubov-Kubo-Mori inner product, or more generally the corresponding positive-definite metric matrix on the finite-dimensional operator space under consideration.
In that setting, projector geometry is no longer Euclidean in the naive coordinate basis. However, after Euclideanisation by the metric square root, -orthogonal projectors become ordinary Euclidean projectors, and the weighted signal map becomes an ordinary matrix to which the same singular-value theory applies.
This means that once a linear quantum fluctuation correction is identified in BKM geometry, the following objects transfer:
-
1.
the visible signal retained by a rank-constrained observable sector,
-
2.
the optimal rank- envelope,
-
3.
the retention fraction and hidden fraction,
-
4.
the stable-rank complexity invariant,
-
5.
the alignment theorem and random-observer baseline,
-
6.
the spectroscopy hierarchy.
This is a much stronger statement than a vague analogy between classical Fisher geometry and quantum BKM geometry. It is a transfer of the projector-level visibility law, and it should be read at the level of conditional visibility geometry rather than as a complete shadow or detectability transfer.
It also explains why the operator-space step matters even before the physical quantum correction object is identified in full generality. Once such an object is written in weighted Gram form, the whole finite-observation geometry transfers unchanged.
9.5 What transfers and what does not
The abstract metric theorem makes the scope of the operator-space extension very clear.
What transfers is the weighted linear algebra of visibility. If a correction operator in a finite-dimensional metric geometry admits a weighted signal factorisation, then the projector formula, Ky Fan envelope, retention hierarchy, stable-rank invariant, alignment theorem, and spectroscopy corollary all transfer by Euclideanisation. The backbone-whitened detectability geometry of Section 6 does not yet transfer, because no identified quantum correction operator has yet been shown to support the corresponding shadow construction.
What does not automatically transfer is the physical identification of the correction operator itself. In the classical Markov setting, the bridge theorem provides this identification through the reduced-coordinate DV Hessian analysis. In the quantum setting, one still needs a physically justified linear fluctuation object in the appropriate BKM geometry before the abstract weighted theory can be applied. At the algebraic level, the missing step is a BKM-antisymmetry or completion-of-the-square cancellation for the quantum skew channel, which is not automatic for the commutator map in BKM geometry.
This distinction is essential and must remain visible in the final paper. The work proves a classical bridge and an abstract weighted geometry theorem. It then uses the latter to formulate a disciplined linear quantum extension. It does not claim a fully general nonlinear quantum Donsker-Varadhan theorem.
It shows that the classical and quantum parts of the paper are related in the right order. The classical theory is exact because both the physical bridge and the visibility geometry are known. The operator-space part is exact at the geometric level and conditional at the physical fluctuation-identification level.
The next section turns to the linear quantum fluctuation extension itself. It shows how the weighted visibility law fits naturally into recent work on BKM geometry, restricted information, and quantum nonequilibrium thermodynamics.
10 Linear quantum fluctuation extension
10.1 Quantum fluctuation object in BKM coordinates
The abstract weighted geometry of Section 9 shows that the finite-observation machinery transfers once a physically meaningful correction object is identified in a finite-dimensional metric geometry. In the quantum nonequilibrium setting, the natural candidate metric is the Bogoliubov-Kubo-Mori metric, which already appears in recent work on slow quantum nonequilibrium steady-state thermodynamics and geometric dissipation [21, 22, 23]. BKM is used here because of its fluctuation and linear-response relevance, not because it is the unique monotone quantum Fisher metric in the Petz family; different monotone choices would induce different weighted observer geometries [33].
The guiding idea is the following. In the classical Markov setting, Section 3 identifies a fluctuation correction object whose visible share under finite-rank observation is governed by a weighted signal operator. The quantum linear extension seeks the corresponding object in BKM-symmetrised operator coordinates. Once such an object is written in weighted Gram form, the visibility law of Sections 4 to 7 follows from the abstract metric theorem.
We therefore work in a finite-dimensional operator space , equipped with a positive-definite BKM metric matrix . The relevant observable sectors are -orthogonal projectors, and the physically meaningful fluctuation object is a linearised correction operator associated with a quantum nonequilibrium steady-state generator. In the paper, we do not attempt to construct the full nonlinear quantum analogue of the classical bridge. Instead, we identify the precise linear fluctuation setting in which the weighted visibility theory transfers.
This distinction matters. The quantum part of the paper is not a speculative appendix to the classical theorem. It is the operator-space continuation that becomes exact once the fluctuation object has been linearised and expressed in the correct BKM geometry. What transfers here is conditional visibility geometry in linearised BKM coordinates, not yet the full backbone-whitened detectability geometry of the classical shadow construction.
10.2 Quantum observable envelope
The operator-space transfer theorem of Section 9 implies that once a quantum fluctuation correction is written in weighted Gram form relative to the BKM metric, its visible signal under finite observation is governed by the same envelope hierarchy as in the classical case. The consequences listed below are therefore conditional: they apply only once a physically meaningful quantum fluctuation correction with the required weighted Gram representation has been identified.
Concretely, let be a finite-dimensional positive semidefinite quantum fluctuation correction acting on the BKM operator space, and assume that it admits a weighted signal factorisation
| (10.1) |
where ♯ denotes the adjoint with respect to the BKM metric. Let be an -orthogonal projector of rank . Then the visible quantum nonequilibrium signal is
| (10.2) |
and by the abstract theory this is the projected signal energy of the Euclideanised operator , with and .
The immediate consequences are direct quantum analogues of the classical theorems:
-
1.
the exact rank- visible envelope is given by the Ky Fan top-singular-energy profile of the Euclideanised quantum signal operator,
-
2.
the exact retention fraction is the cumulative singular-energy fraction,
-
3.
the effective observability complexity is the stable rank of the Euclideanised quantum signal operator,
-
4.
the optimal quantum finite observer is the projector onto the dominant singular front,
-
5.
the envelope hierarchy is a spectroscopy of the visible quantum nonequilibrium signal.
Thus, at the level of weighted signal geometry, the classical and linear quantum finite-observation theories are formally identical. What changes is not the projector-level visibility law, but the physical origin and interpretation of the fluctuation object.
This is precisely where the recent BKM and quantum information-geometric literature becomes relevant. BKM geometry is already known to control nonadiabatic entropy production and path-action structure in slow quantum nonequilibrium steady-state transitions [21]. Quantum Fisher decompositions also distinguish incoherent and coherent geometric contributions to thermodynamic and dynamical constraints [22]. The paper adds a complementary statement: once the fluctuation correction is placed in BKM metric form, finite observation has a spectral visibility law.
10.3 Restricted information and quantum observation
The quantum extension is also the natural point of contact with recent work on restricted information and observation-dependent thermodynamic quantities.
Rubino, Brukner, and Manzano show that coarse-grained quantum thermodynamic quantities depend explicitly on observational resolution, even while fluctuation-theorem-type relations survive at each level of access [19]. Pernambuco and Céleri argue that restricted microscopic access should be treated geometrically as a gauge reduction on the space of states, leading to gauge-invariant entropy and fluctuation relations under limited information [20]. These papers differ significantly in mathematical machinery, but they share a common message: thermodynamic content depends on what the observer can resolve.
The present theory gives a new layer beneath that message. In the linear BKM fluctuation regime, restricted observation is not only a question of coarser thermodynamic bookkeeping or gauge-reduced distinguishability. It is a singular-value problem. The observer’s access to quantum nonequilibrium structure is determined by the spectrum and singular-mode geometry of the weighted fluctuation signal.
This suggests a clean conceptual synthesis. Restricted information determines which operator-space directions are accessible. The BKM metric determines the physically correct geometry of fluctuation comparison. The weighted signal operator determines how much nonequilibrium structure those accessible directions can actually retain. In the linear BKM regime, the restricted-information question therefore becomes precise: identify a physically meaningful correction admitting , and the finite-observation visibility theory then follows from the metric-universal Ky Fan framework. In this sense, the theory does not compete with the restricted-information literature. It completes one of its missing linear-algebraic pieces in the fluctuation setting.
10.4 Limits of the present quantum theorem
The operator-space transfer should not be overstated. As stressed at the end of Section 9, the paper proves a classical bridge and an abstract weighted visibility law, and then uses the latter to formulate a disciplined linear quantum extension. It does not claim a general nonlinear quantum Donsker-Varadhan theory, nor a complete quantum shadow theorem at the same level of explicitness as in the classical Markov setting. In particular, the full backbone-whitened detectability geometry of the classical shadow construction has not yet been identified and tested in operator-valued form.
Three limitations are especially important.
First, the physical identification of the quantum fluctuation correction remains linearised. The paper says that if the correction admits the appropriate weighted Gram representation in finite-dimensional BKM geometry, then the finite-observation machinery transfers. It does not derive that representation in full generality from first principles for arbitrary GKLS dynamics.
Second, the operator-space theory does not yet address noisy or non-projective finite observation channels at the same level of completeness. The projectors of the current paper describe sharp finite-rank observation sectors in the underlying geometry. General measurement channels and faulty observation maps remain a next step.
Third, the current paper does not attempt to settle the nonlinear quantum analogue of the diagonal-qubit falsifier and related beyond-quadratic issues discussed in the recent literature on partial observation and quantum thermodynamics. The paper stays deliberately at the linear fluctuation level where the weighted visibility geometry is exact.
These limitations mark the boundary of the work and indicate the next technical steps.
11 Worked Examples
These benchmarks are selected calibration points for the operator theory. Each is read through the same finite-observation ladder: skew source, backbone-weighted signal, hidden spectral tail under rank constraint, and the whitened spectrum controlling detectability against the detailed-balance backbone.
11.1 A four-state two-cycle network from the entropy-estimation literature
We take the four-state, five-link, two-cycle network used in the transition-based waiting-time literature, with rates given in Appendix E, Table IV of van der Meer, Ertel, and Seifert [37]. In that source problem, the observed link is the transition pair , and the forcing parameter enters only through the rates on that link. At the benchmark value
| (11.1) |
the rates become
| (11.2) |
This first benchmark is genuinely multicyclic, small enough for transparent computation, and already recognised in the entropy-estimation literature. It therefore provides a compact test of the bridge, envelope, shadow, and detectability results on a standard network.
11.2 Envelope benchmark and the induced observed-link sector
For this generator the stationary law is
| (11.3) |
The reduced Fisher space has dimension . The computed weighted signal operator has singular values
| (11.4) |
so the active nonequilibrium geometry is rank two. In reduced dimension three this is structural: the real skew carrier has rank at most two, so there are at most two nonzero singular values. The weighted stable rank is
| (11.5) |
The Ky Fan visibility levels are therefore
| (11.6) |
which gives retained fractions
| (11.7) |
Thus a single unconstrained optimal observable direction already retains about of the full Gaussian nonequilibrium signal, while two directions recover the entire active sector. The random rank-one baseline is .
The bridge relation is also numerically sharp in this example. Direct computation gives
| (11.8) |
which is a finite-precision numerical reconstruction residual rather than a structural mismatch. The benchmark is therefore not merely illustrative at the level of the envelope. It is also quantitatively consistent with the bridge developed in Section 3.
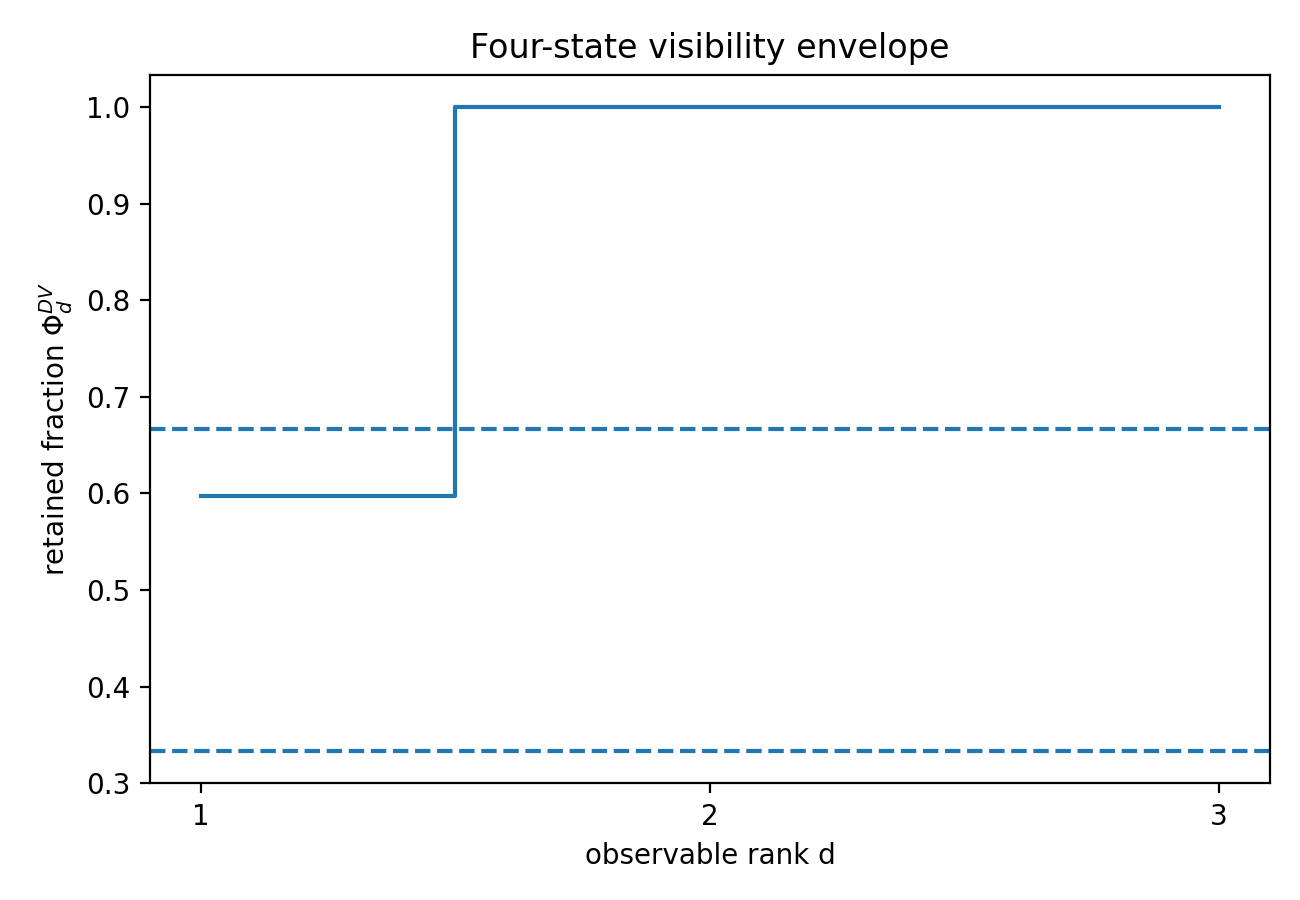
Figure 1 makes the unconstrained envelope structure explicit. To connect the benchmark directly to the source observation pattern, we now instantiate the actually observed link as an orthogonal sector inside the theorem class of the paper.
The waiting-time estimator of [37] is built from transitions along the observed edge . That observable is not literally an orthogonal projector on the reduced Fisher space, so we take its canonical Fisher-orthogonal rank-one surrogate
| (11.9) |
Because , this direction lies naturally in the Fisher tangent space. It is the orthogonal observer induced by the physical access pattern observe only the link, while remaining inside the orthogonal-compression framework of Sections 2 to 6.
For this literature-induced sector we obtain
| (11.10) |
Thus the actual observed edge captures well below the unconstrained optimum , and even below the blind rank-one baseline . At the raw-signal level, the source observable is therefore strongly misaligned with the dominant singular front of .
The shadow statistics tell a more refined story. For the same sector,
| (11.11) |
so in this rank-one case the shadow score is the scalar
| (11.12) |
The reverse Gaussian KL divergence is therefore
| (11.13) |
which gives
| (11.14) |
This already separates two questions that are blurred in much of the partial-observation literature. The physically observed edge is poor as a raw proxy for the full nonequilibrium signal, but it is less poor after backbone normalisation. Indeed, with and , the detectable fraction of the actual observed sector is
| (11.15) |
to be compared with the detectability optimum . At , the observed edge therefore sits below the raw rank-one baseline in visibility, but above the natural rank-one whitened benchmark in backbone-normalised detectability. This is the cleanest indication, on this benchmark, that the detectability landscape is materially flatter than the raw-visibility landscape.
| Observer sector | TV bound | |||
|---|---|---|---|---|
| Random raw baseline / whitened benchmark | – | |||
| Raw-optimal rank-one | ||||
| Observed sector | ||||
| Detectability-optimal rank-one |
Table 1 is the main point of the worked example. It shows that one can now rank concrete observation schemes geometrically. The gap between the observed sector and the raw optimum is an exact alignment deficit, not a vague information-loss slogan. At the same time, the smaller gap in shows that backbone-normalised detectability can be materially less pessimistic than raw signal retention.
11.3 A short forcing sweep on the actual observed sector
Because the source family is parametrised by a single force acting on the observed link, it also furnishes a natural one-parameter sweep. Figure 2 plots
| (11.16) |
for the same induced observed-link sector .
Across the range , the raw retained fraction rises from about to about , while the shadow trace rises from about to about . The separation is already clear at moderate forcing: at , the observed sector still retains only of the total raw signal, but its backbone-normalised shadow strength is already . This is the distinction between raw visibility and backbone-normalised detectability formalised in Section 6.
The worked benchmark shows that the present geometry can compare the actual source observable with the visibility-optimal and detectability-optimal observers, and can track how that gap changes across a physically motivated forcing family.
11.4 A five-state ribosome proofreading benchmark from the speed-accuracy literature
The four-state benchmark shows that the theorem package can compare actual and optimal observers on a standard partial-observation network. We now test the same machinery on a biologically canonical proofreading model. Banerjee, Kolomeisky, and Igoshin analyse aa-tRNA selection by the E. coli ribosome through a five-state kinetic-proofreading network, together with hyperaccurate and error-prone mutants, and argue that the experimentally relevant regime is organised primarily by speed, with energetic proofreading cost as an additional constraint rather than by direct minimisation of error alone [38].
To place that system inside the finite-observation framework of the present paper, we use the closed turnover continuous-time Markov model on the state set
| (11.17) |
where is the free ribosome, and are the cognate branch before and after hydrolysis, and and are the near-cognate branch before and after hydrolysis. The right-pathway rates and discrimination factors are taken directly from the Banerjee supporting-information tables for the wild type (WT), hyperaccurate mutant (HYP, ), and error-prone mutant (ERR, ) ribosomes [38].
As in Banerjee’s translation analysis, we impose the nearly irreversible choices and , and derive from the cycle constraint. The generator used here is not the backward first-passage operator from the source paper. It is the ergodic turnover generator in which both catalytic completion and proofreading reset return the system to the free state .
Before applying finite observation, we validate the reconstruction against the source biology. The stationary fluxes recover the correct speed and error ordering
| (11.18) |
and the flux-based proofreading cost agrees with the analytic Banerjee formula to relative error below for all three variants. The benchmark is a source-locked turnover model that reproduces the intended biological regime before any spectral analysis is performed.
11.5 Raw spectral concentration and interpretation of effective complexity
The reduced Fisher tangent space has dimension for each ribosome variant. Figure 3 and Table 2 show the singular spectrum of the weighted signal operator and the associated Ky Fan retention hierarchy.
Across all three variants the raw nonequilibrium signal is sharply concentrated. The weighted stable rank lies in the narrow interval
| (11.19) |
while the rank-one retained fractions satisfy
| (11.20) |
More importantly, two observer directions already recover almost the entire Donsker-Varadhan correction:
| (11.21) |
Thus the active signal is effectively rank two in a four-dimensional reduced Fisher space, despite the fact that the underlying proofreading network is multibranch and is usually discussed through several competing biological performance measures. Within the raw finite-observation geometry, the benchmark exhibits a pronounced appearance of spectral simplicity despite topological and functional richness: topological complexity does not imply spectral complexity.
| Variant | top | |||||
|---|---|---|---|---|---|---|
| WT | 1.4709 | 0.6799 | 0.9867 | 2 | 2 | 0.324613 |
| HYP | 1.4130 | 0.7077 | 0.9913 | 2 | 2 | 0.320700 |
| ERR | 1.5166 | 0.6594 | 0.9504 | 2 | 4 | 0.327211 |
11.6 Backbone-normalised detectability and biologically legible observer directions
The whitened detectability spectrum sharpens the comparison between variants. Figure 4 shows that WT and HYP have an almost perfectly rank-two detectability structure: in both cases a nearly degenerate leading pair at
| (11.22) |
dominates, while the residual tail is tiny,
| (11.23) |
Consequently, two detectability directions already capture more than of the backbone-normalised signal for WT and HYP. The ERR mutant shows a more mixed geometry. Its leading pair remains dominant,
| (11.24) |
but the lower pair remains substantial,
| (11.25) |
so rank two captures only about of detectability and one needs full rank to exceed the threshold. Raw retention is therefore highly concentrated in all three variants, but detectability distinguishes the speed-optimised WT and HYP variants from the more diffuse ERR mutant.
Figure 5 shows that the dominant observer directions are also biologically legible. Up to the usual overall sign convention, the top raw observer loads primarily on the cognate branch , while the subdominant direction separates cognate from near-cognate structure. The top detectability observer places its weight mainly on the hydrolysis stage, which is consistent with the role of as the main distinguishability channel after backbone normalisation and with hydrolysis as the natural discrimination checkpoint of the proofreading cycle. The observer geometry is therefore not only low rank. It is interpretable in terms of the proofreading mechanism itself. As the matched-null comparison later makes clear, however, the resulting low-rank concentration is not by itself specific evidence for proofreading architecture.
11.7 Robustness under hydrolysis-rate variation
Banerjee’s own speed-accuracy analysis identifies the hydrolysis step as a key kinetic control axis for the WT ribosome [38]. We therefore perform a one-parameter finite-observation sweep over while keeping the remaining WT parameters fixed. Figure 6 shows that the low-rank picture is robust across this family. The rank-one retained fraction stays above , the rank-two retained fraction stays above , the weighted stable rank remains close to , and the top detectability eigenvalue rises smoothly toward a plateau near . Across the hydrolysis-rate sweep, the dominant detectability structure remains low-rank and varies smoothly. There is no sharp spectral transition in the biologically relevant band. The spectral simplicity of the WT proofreading network is therefore a structural feature of the benchmark family, not a knife-edge artefact of one fitted parameter set.
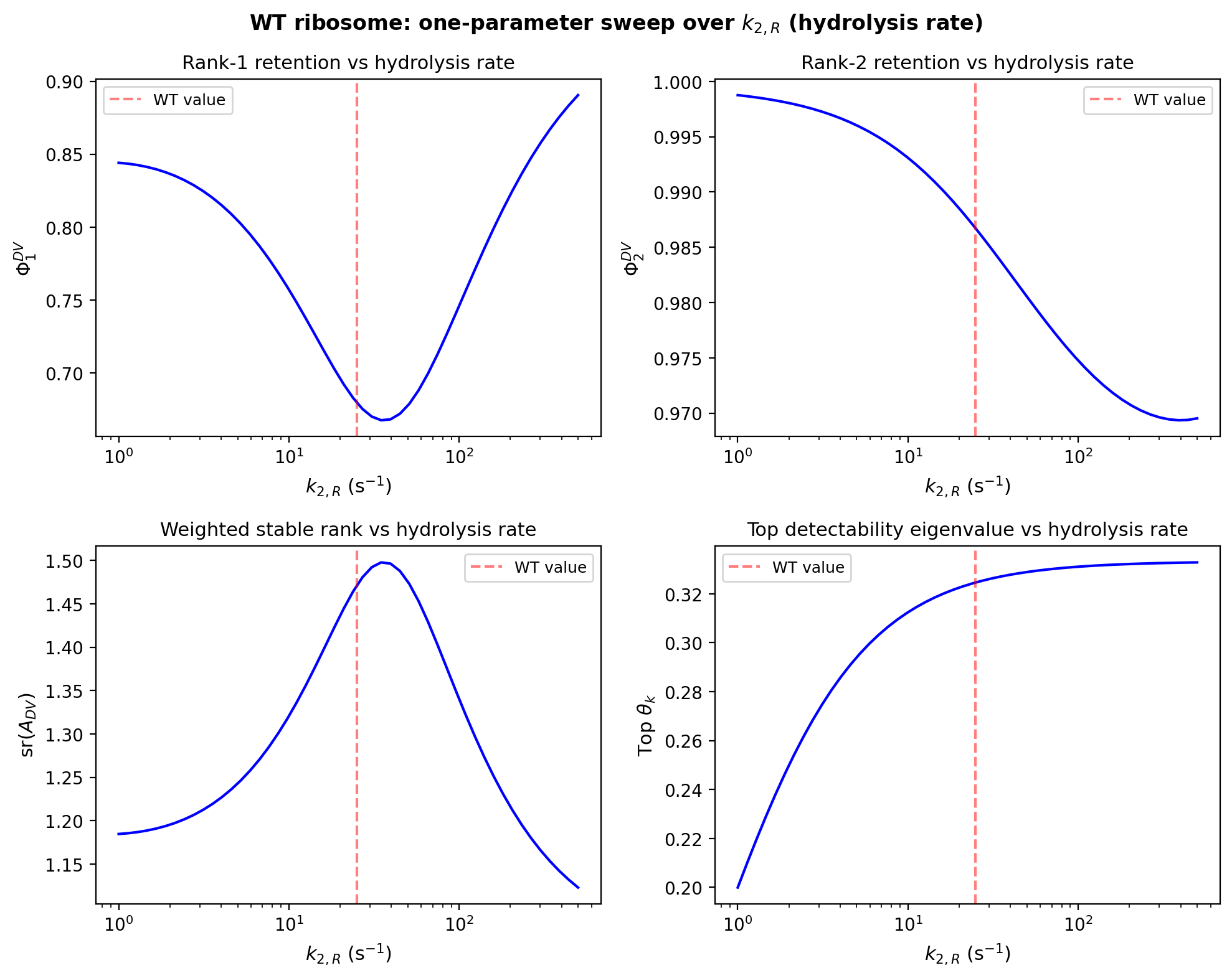
Taken together, the Banerjee benchmark upgrades the theorem package from a compact literature network to a biologically canonical proofreading system with experimentally grounded parameters and variant structure. The conclusion is unusually clean. A network that is functionally rich enough to support speed-accuracy-cost trade-off analysis can still be spectrally simple in the finite-observation geometry. In this benchmark, most of the nonequilibrium correction lives in two observer directions, and the remaining distinction between variants becomes visible only after backbone whitening.
11.8 A matched random null for the Banerjee benchmark
The Banerjee ribosome benchmark is useful, but its structural interpretation must be stated carefully. We therefore compare the WT proofreading network against a matched null ensemble of dense random five-state nonequilibrium CTMCs with the same mean exit-rate scale and with total DV energy restricted to a narrow band around the real benchmark. The null ensemble was designed to answer a specific question: is the strong raw rank-two compression in the ribosome case a special fingerprint of proofreading architecture, or is it largely a dimensional effect of working in a four-dimensional reduced Fisher space?
This random-ensemble perspective is also consonant with recent work showing that, in broad classes of random Markov models, many irreversibility-sensitive observables are controlled primarily by heterogeneity rather than by asymmetry alone except near symmetry [39].
The answer is the latter. As Figure 7 shows, across the primary raw metrics the real Banerjee WT point sits close to the middle of the matched null distribution rather than in an extreme low-rank tail. In particular,
| (11.26) |
so the WT point sits close to the middle of the sampled null ensemble on all three raw metrics. Thus the Banerjee network remains an important demonstration that the finite-observation machinery can be applied to a real biochemical system with biologically legible observer directions, but the raw low-rank compression itself cannot be claimed as a special consequence of proofreading architecture.
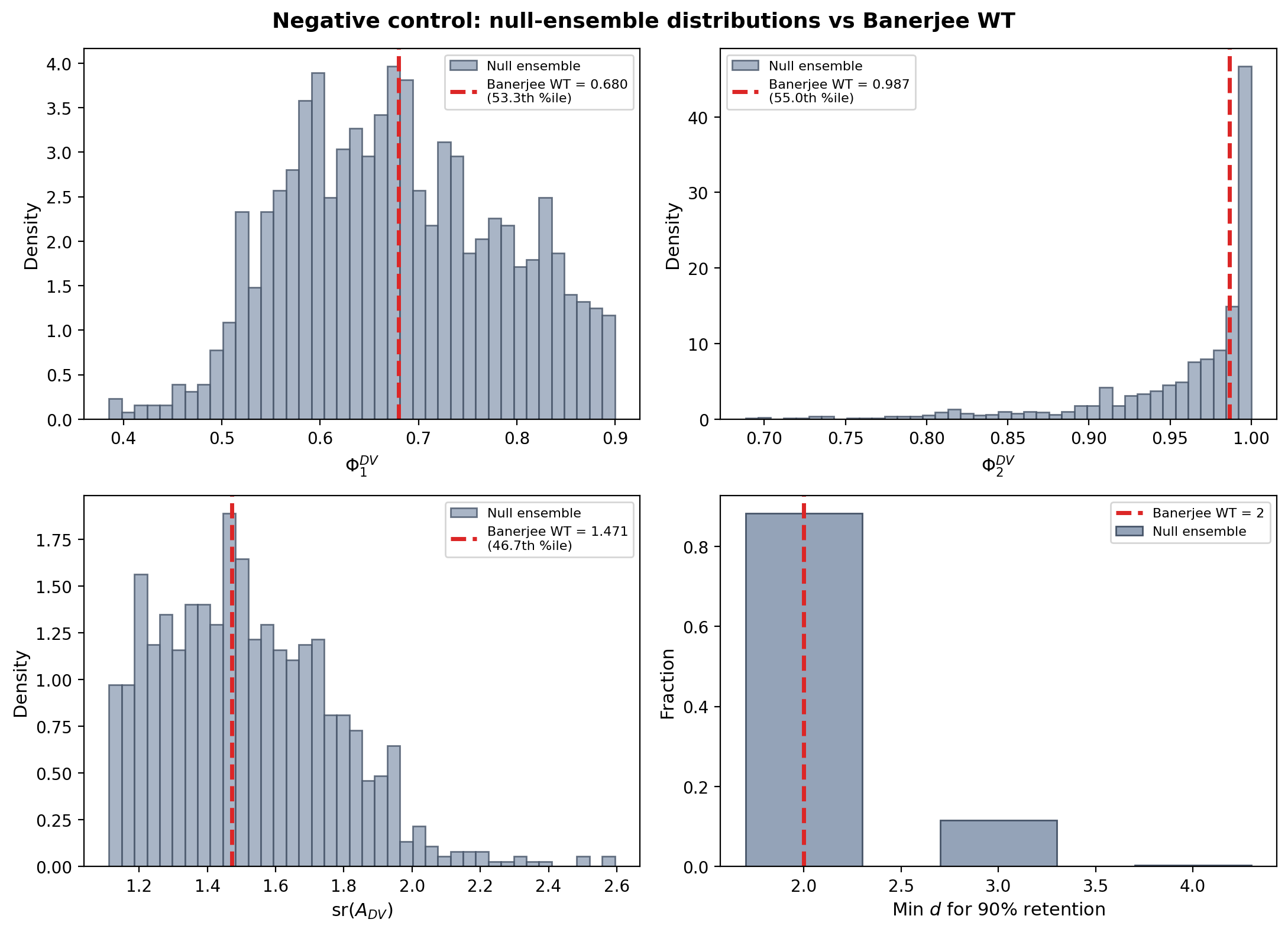
11.9 A force-driven kinesin benchmark from the molecular-motor literature
To test whether the same spectral compression extends beyond proofreading, we next turn to the chemomechanical kinesin model of Liepelt and Lipowsky [40, 41]. This benchmark is mechanistically distinct from the Banerjee ribosome network. Its primary form is a six-state motor with two competing chemomechanical cycles and one purely dissipative cycle, together with explicit load-force control through a mechanical load-distribution factor and force-sensitive chemical prefactors. The supplement also gives a reduced seven-state small-load extension in which a doubly ADP-bound state opens an additional forward cycle. We use the source-locked six-state model at arbitrary load, and the reduced seven-state model only in the zero-load regime where the source supplement explicitly justifies that truncation and supplies the extra rates.
For the six-state model the transition rates are built in the source convention as
| (11.27) |
with rate constants from Table I of [40], force parameters from Table II and Appendix A of [41], and the backward-cycle rate imposed as in the source derivation. The reduced seven-state model retains only the additional edges and , again as prescribed in Appendix D of [41].
Before applying finite observation, we validate the reconstruction against the source dynamics: both force-data parametrisations reproduce a stall force near , the six-state model reproduces the source asymmetry between - and -dependence at zero load, and the reduced seven-state model restores the missing high-ADP slowdown while producing the predicted crossover to the added cycle at .
11.10 Raw concentration across force and concentration
The six-state kinesin benchmark is sharply low-rank across the tested regimes. At zero load, all three published source parametrisations are essentially rank one in the raw Donsker–Varadhan correction:
| (11.28) |
with weighted stable rank in the narrow interval
| (11.29) |
Thus a single observer direction already captures more than of the nonequilibrium correction in every zero-load case.
Figure 8 shows how this picture evolves under load for the two source force-data parametrisations. Broadening does occur near stall, but it is physically transparent rather than pathological. For the [15] fit, rank-one retention drops from at zero load to about near , while the weighted stable rank rises from to .
For the [9] fit, the broadening is milder, with and at . In both cases, however, the low-rank tendency persists away from the stall region. This is the behaviour one would expect if the singular front is controlled by the competition between forward and backward chemomechanical cycles: the spectrum is narrow when one cycle dominates and broadens only when the cycle currents come close to balance.
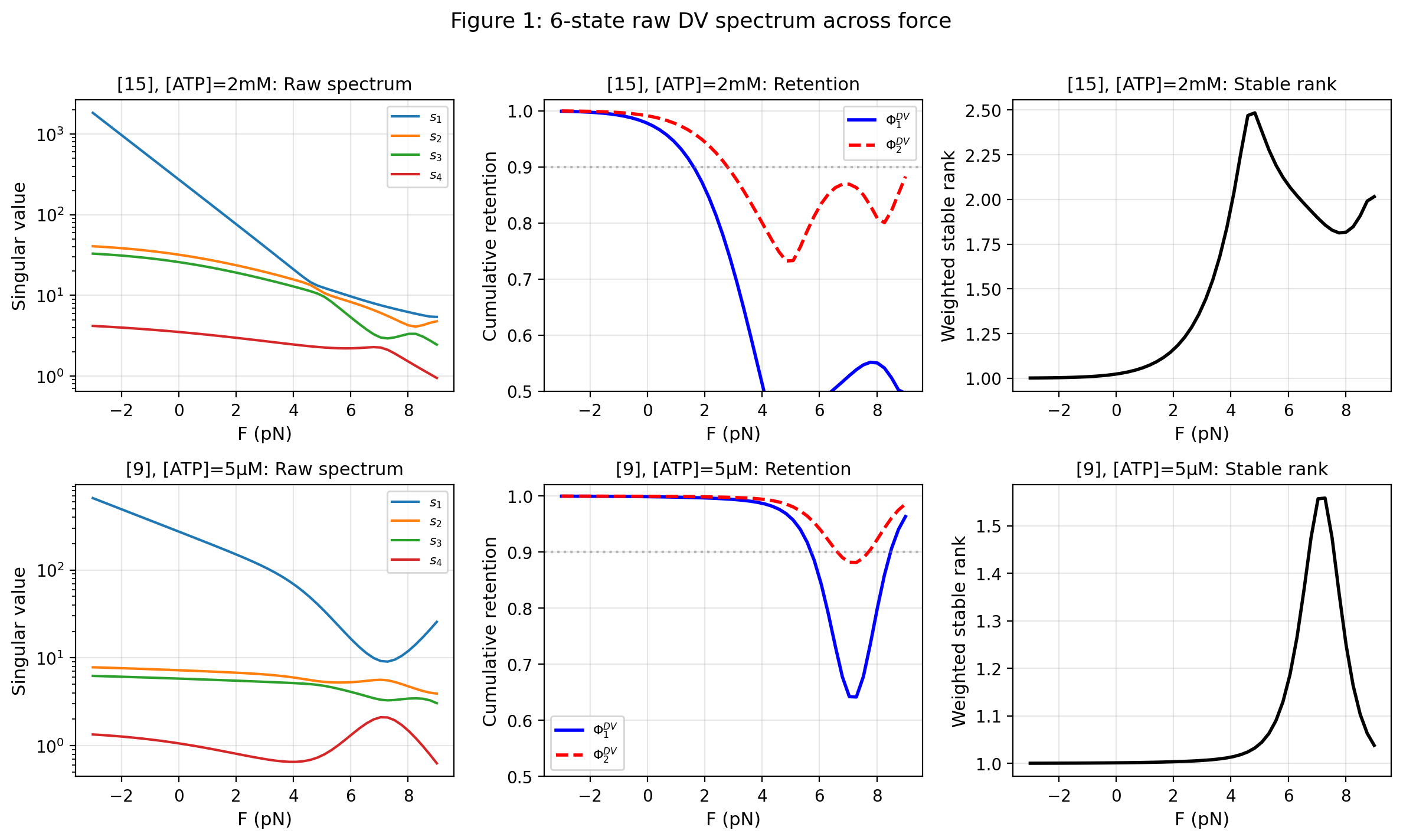
The zero-load concentration stress test in Figure 9 shows a second important feature. The six-state geometry is almost insensitive to , for which the source paper already reports good kinetic agreement, while produces only a mild spectral shift even in the regime where the six-state velocity law is known to underpredict the slowdown. For the [12] parametrisation at , the raw rank-one retained fraction stays near throughout the -sweep and rises only slightly, from about to , over four decades of . Thus the kinetic failure of the six-state model at high ADP is not a failure of raw spectral concentration.
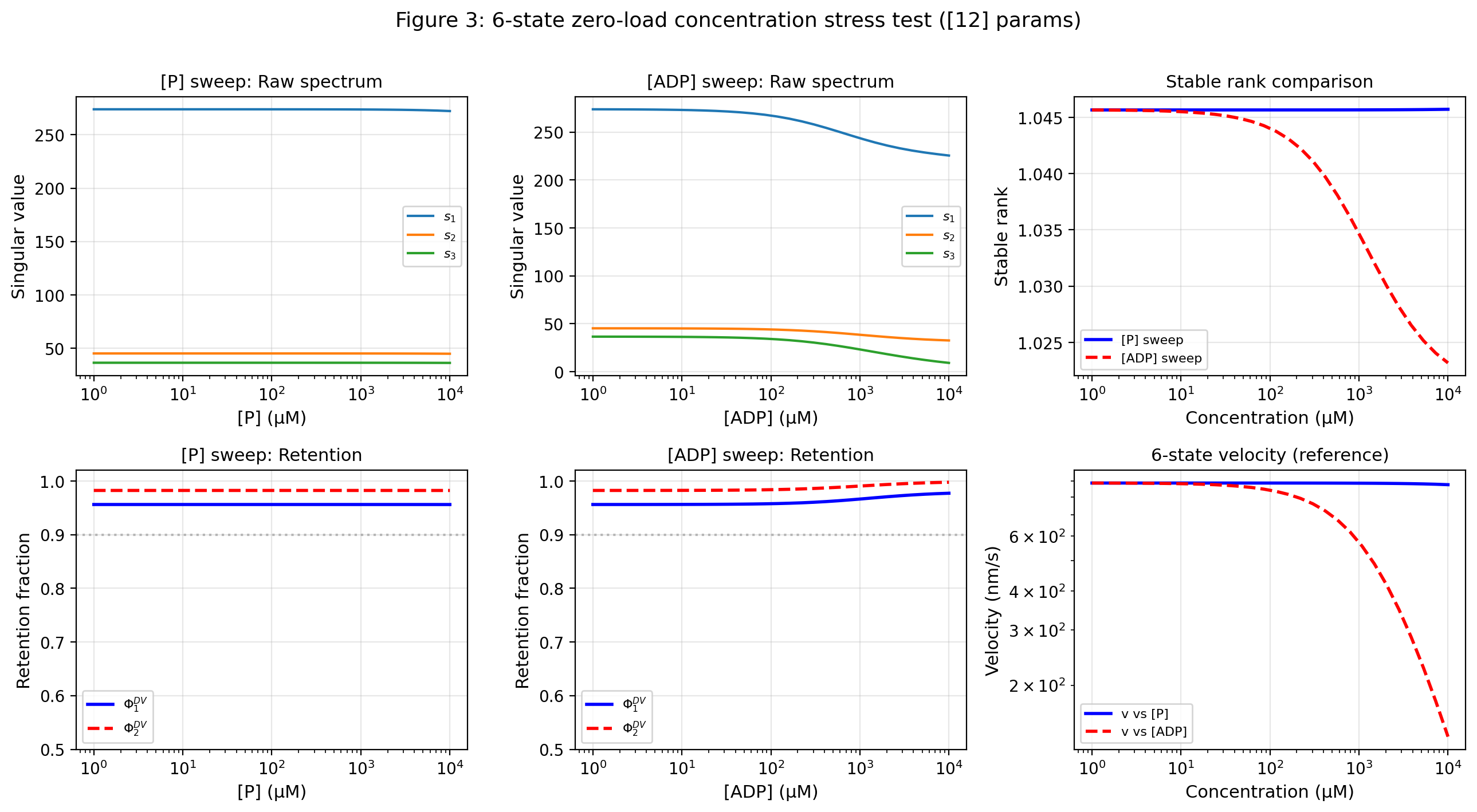
11.11 Backbone-normalised detectability and the reduced seven-state extension
The whitened detectability spectrum is materially broader than the raw spectrum. Figure 10 shows that the top detectability eigenvalue remains of order to , but the detectability mass is spread over more directions than the raw DV correction. In the representative six-state cases of Table 3, one typically needs rank four to exceed the detectability threshold even when the raw signal is already more than concentrated in rank one. This reproduces, in a mechanochemically different system, the same separation between raw visibility and backbone-normalised detectability that was already visible in the ribosome benchmark.
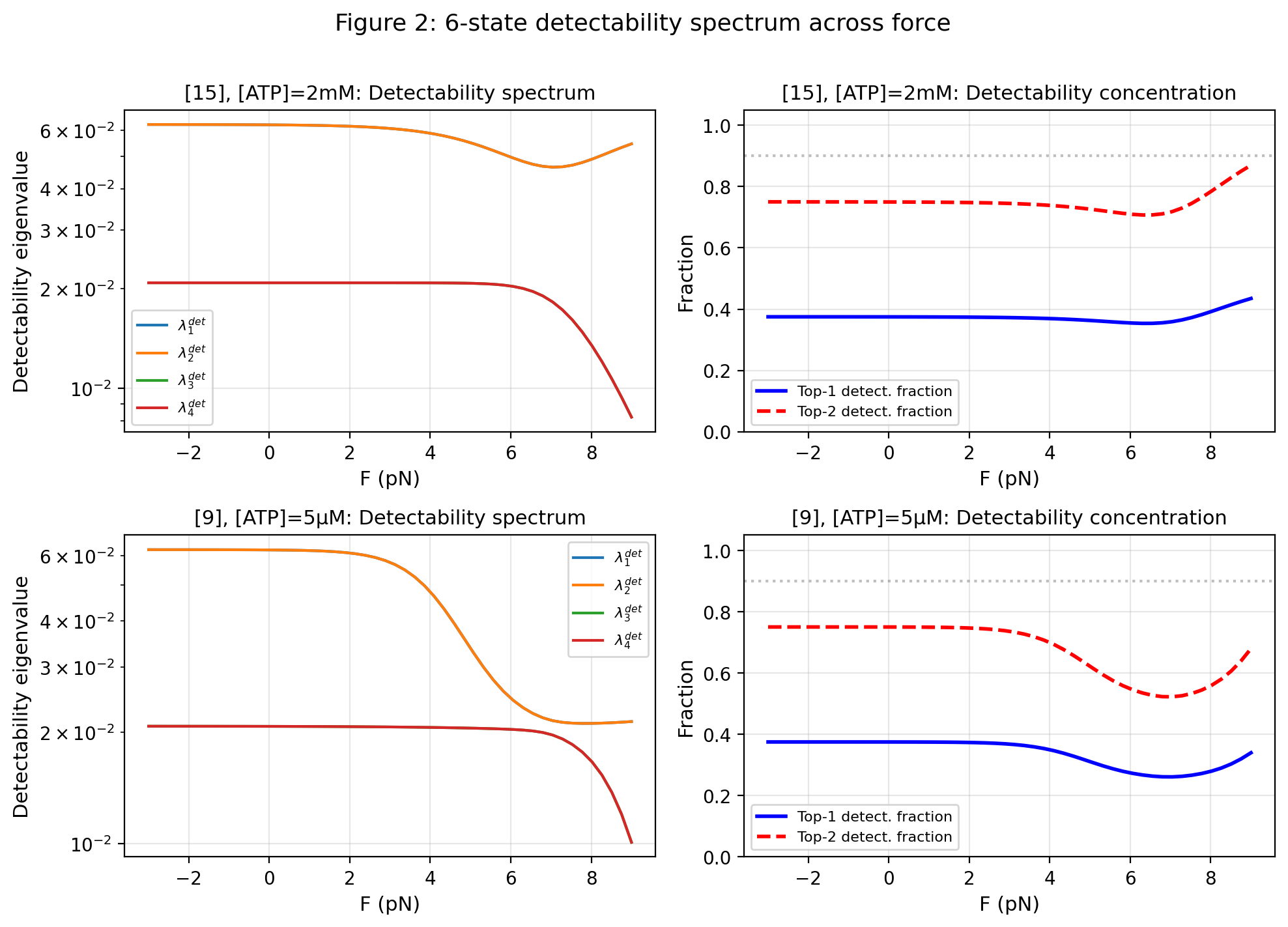
The reduced seven-state model strengthens the cross-model recurrence case further. Its purpose in the source literature is to repair the missing -dependence of the six-state motor by adding a doubly ADP-bound state and the corresponding forward cycle . In the finite-observation geometry, however, the added mechanistic structure does not broaden the signal. Figure 11 shows that the rank-one retained fraction actually increases with , from about at to at , while the weighted stable rank falls from to . At the same time, the top detectability eigenvalue decreases from to , and the minimal detectability rank for retention improves from four to two. The source paper’s extra cycle becomes dynamically important without destroying the low-rank observer geometry.
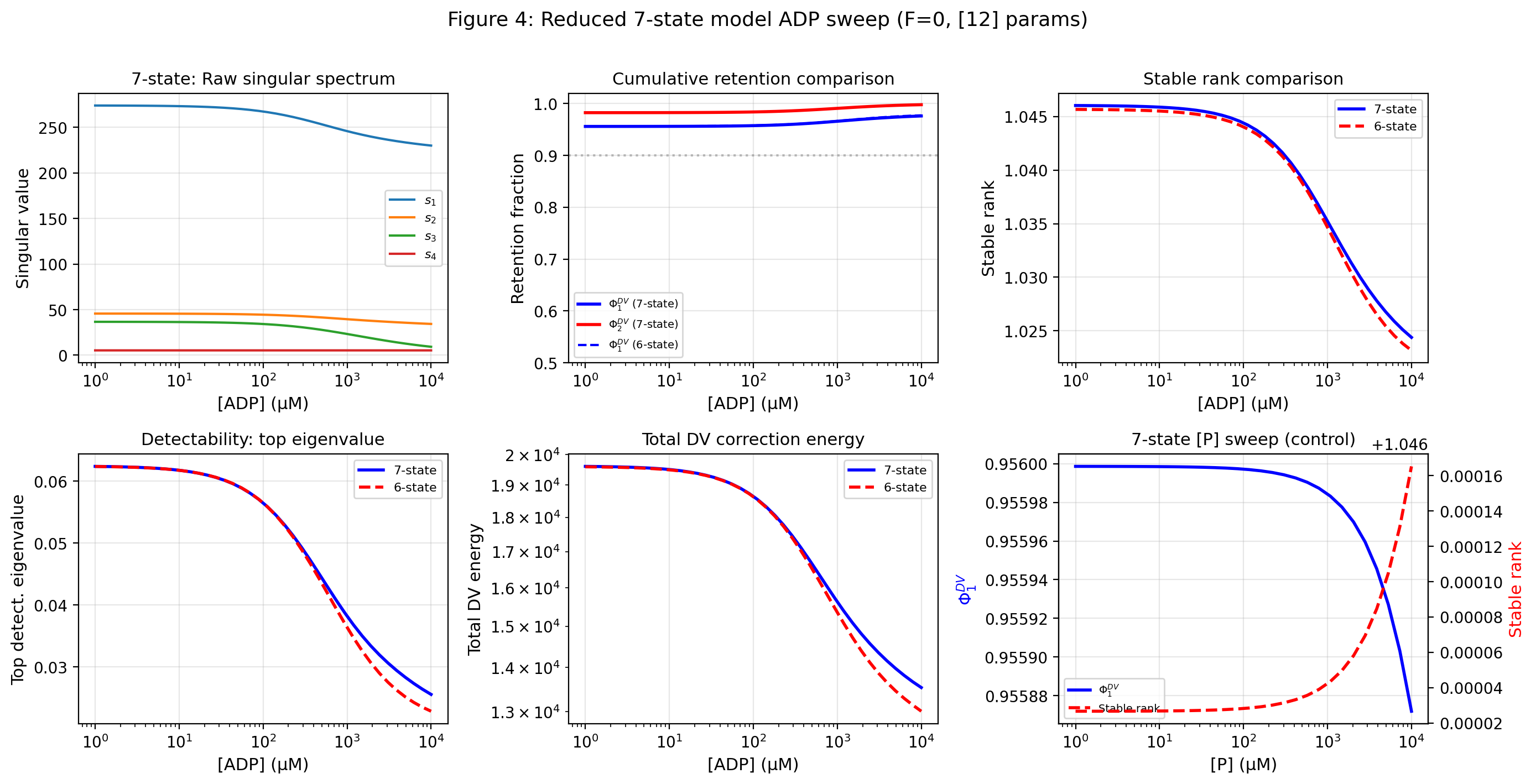
| Case | top | ||||||
|---|---|---|---|---|---|---|---|
| 6s,[15], | 6 | 0.9777 | 0.9911 | 1.0228 | 0.0623 | 1 | 4 |
| 6s,[15], | 6 | 0.5260 | 0.8695 | 1.9012 | 0.0465 | 3 | 4 |
| 6s,[9], | 6 | 0.9988 | 0.9995 | 1.0012 | 0.0623 | 1 | 4 |
| 6s,[12], | 6 | 0.9563 | 0.9825 | 1.0457 | 0.0624 | 1 | 4 |
| 7s,[12], | 7 | 0.9740 | 0.9966 | 1.0267 | 0.0282 | 1 | 2 |
Figure 12 shows that the leading observer directions remain structured rather than diffuse. In the six-state family, the dominant raw and detectability directions concentrate on only a few numbered states at a time, and in the seven-state ADP regime the new state 7 enters coherently rather than spreading weight uniformly across the enlarged network. This again points to a low-dimensional active nonequilibrium core rather than to generic high-dimensional mixing.
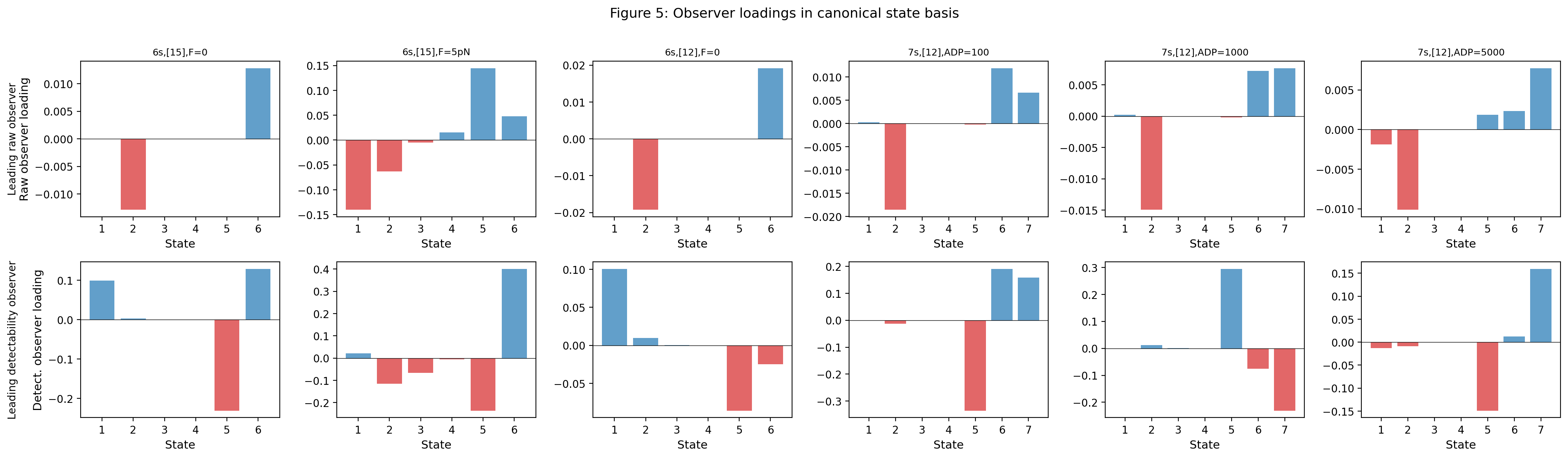
Taken together, the kinesin benchmark materially strengthens the case for cross-model recurrence. The Liepelt–Lipowsky motor is not a proofreading network. It has competing chemomechanical cycles, explicit load-force control, and, in the reduced seven-state extension, a third forward cycle that becomes dominant at high ADP. Yet the finite-observation geometry is at least as concentrated as in the Banerjee ribosome benchmark across most of the tested regimes. The one place where concentration weakens, near stall, is physically transparent: it is exactly where the forward and backward motor cycles come closest to balance. This is therefore not a failure of the low-rank theory but one of its clearest mechanistic confirmations.
11.12 Matched negative controls for the kinesin motor benchmark
Unlike the Banerjee benchmark, the kinesin benchmark behaves differently. Here the positive result survives matched negative controls. We compare three real operating points against graph-matched nonequilibrium control ensembles: anchor A, the six-state motor at zero load; anchor B, the same six-state model near stall; and anchor C, the reduced seven-state model at zero load and high ADP. Two control classes are used. NC1 keeps the graph but replaces the structured motor rates by random positive rates. NC2 is stricter: it keeps the graph and approximately matches the stationary law while randomising the nonequilibrium edge asymmetry.
At the two main low-rank anchors, the real motor is substantially more concentrated than the controls, as shown in Figure 13. For anchor A the real six-state motor has
| (11.30) |
placing it above all sampled NC1 controls and above most sampled values in the stricter -matched NC2 ensemble. For anchor C the reduced seven-state model has
| (11.31) |
placing it above nearly all sampled NC1 controls and above most sampled NC2 controls. Thus the low-rank concentration is not a generic consequence of graph size or edge count alone, and it is only partly explained by the stationary-law profile.
The one exception is the near-stall anchor B, which is now taken at the same operating point reported in Table 3. At this anchor the real motor becomes less concentrated than the matched random controls, with
| (11.32) |
placing the real point below most sampled random controls. The qualitative conclusion is unchanged but now better calibrated: near stall the real motor is less concentrated than typical controls, though not pathologically so. This is the regime in which the forward and backward chemomechanical cycles compete most strongly. The negative control sharpens the mechanistic reading of the benchmark by identifying the stall region as the place where low-rank concentration weakens.
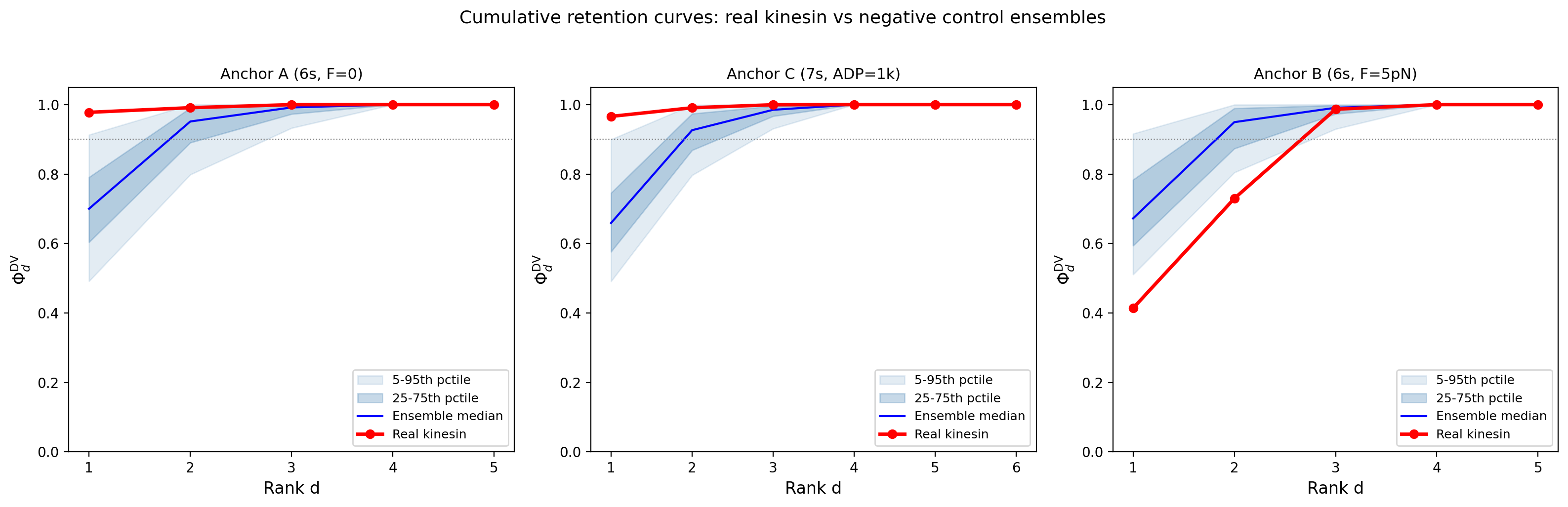
Taken together, the negative controls sharpen the interpretation of both biological examples. For the Banerjee ribosome, the benchmark is valuable mainly as an experimentally grounded and biologically interpretable worked example, but not as evidence that proofreading architecture is unusually low-rank. For kinesin, by contrast, the control ensembles show that the observed spectral compression is not generic to comparable nonequilibrium graphs. The molecular-motor result therefore provides the stronger empirical support for a nontrivial cross-model recurrence claim.
11.13 A ten-state chemotaxis feedback benchmark from the sensory-adaptation literature
The kinesin benchmark shows that strong finite-observation compression can survive outside proofreading and across explicit motor-force control. We now test a larger sensory-feedback system. Sartori, Granger, Lee, and Horowitz study E. coli chemotaxis through a ten-state receptor model with two activity states and five methylation levels , maintained out of equilibrium by SAM-driven methylation [42]. At fixed ligand concentration , the state space is
| (11.33) |
ordered in the implementation as
| (11.34) |
The source kinetics are fixed by the Tar receptor parameters
| (11.35) |
together with the separated timescales
| (11.36) |
and chemical driving
| (11.37) |
We build the fixed-ligand generator directly from the source rate formulas for activity flips and nearest-neighbour methylation moves, and evaluate it at
| (11.38) |
which spans the adaptive regime , its upper edge, and the strongly saturated outside region [42].
Before any spectral analysis, we impose the same source-locking standard used in the previous biological examples. The implemented generator reproduces the ten-state receptor graph of the source model, including all horizontal activity flips and all vertical nearest-neighbour methylation transitions. Local detailed balance holds on the activity sector by construction, and the SAM-driven methylation asymmetry breaks detailed balance at every tested ligand value. The resulting stationary laws are positive and normalised. They also reproduce a key qualitative feature of the source paper: the methylation marginal remains heavily concentrated at the highest methylation level, with Bhattacharyya overlaps above across representative ligand pairs. Thus the benchmark is not an abstract ten-state toy. It is a source-locked receptor model in the specific high-methylation operating regime used by Sartori et al. to discuss the limited memory capacity of the feedback architecture.
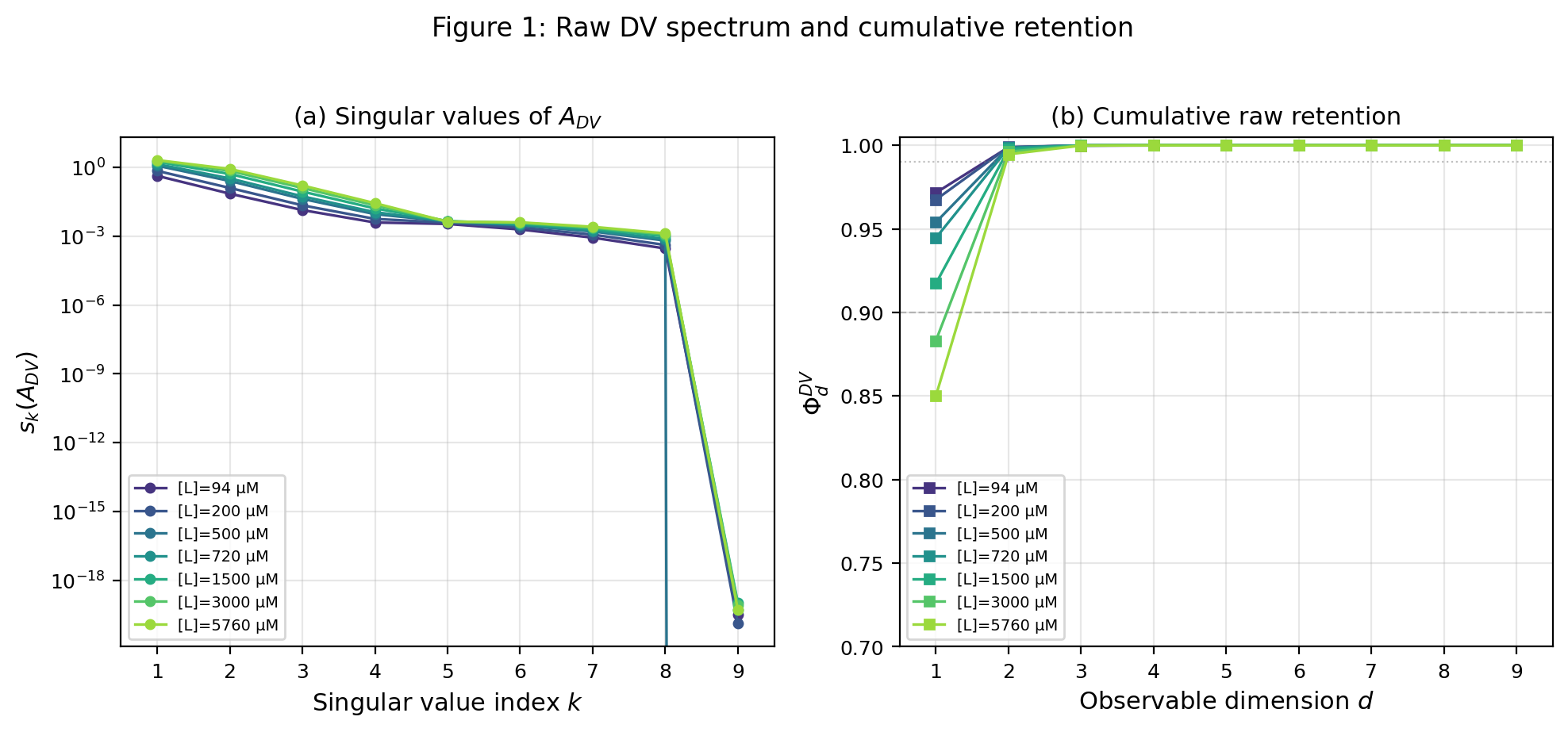
The raw Donsker–Varadhan correction is sharply concentrated across the entire ligand family, as shown in Figure 14. In the adaptive regime, the one-direction retained fraction is already
| (11.39) |
with
| (11.40) |
Even at the largest tested ligand concentration,
| (11.41) |
well beyond , the signal remains strongly compressed:
| (11.42) |
Thus a ten-state sensory-feedback network with a nine-dimensional reduced Fisher space still behaves, in raw finite-observation geometry, almost as a rank-one system. This is materially stronger than the Banerjee proofreading example, where an analogous low-rank conclusion could still be questioned as a small-state-space effect.
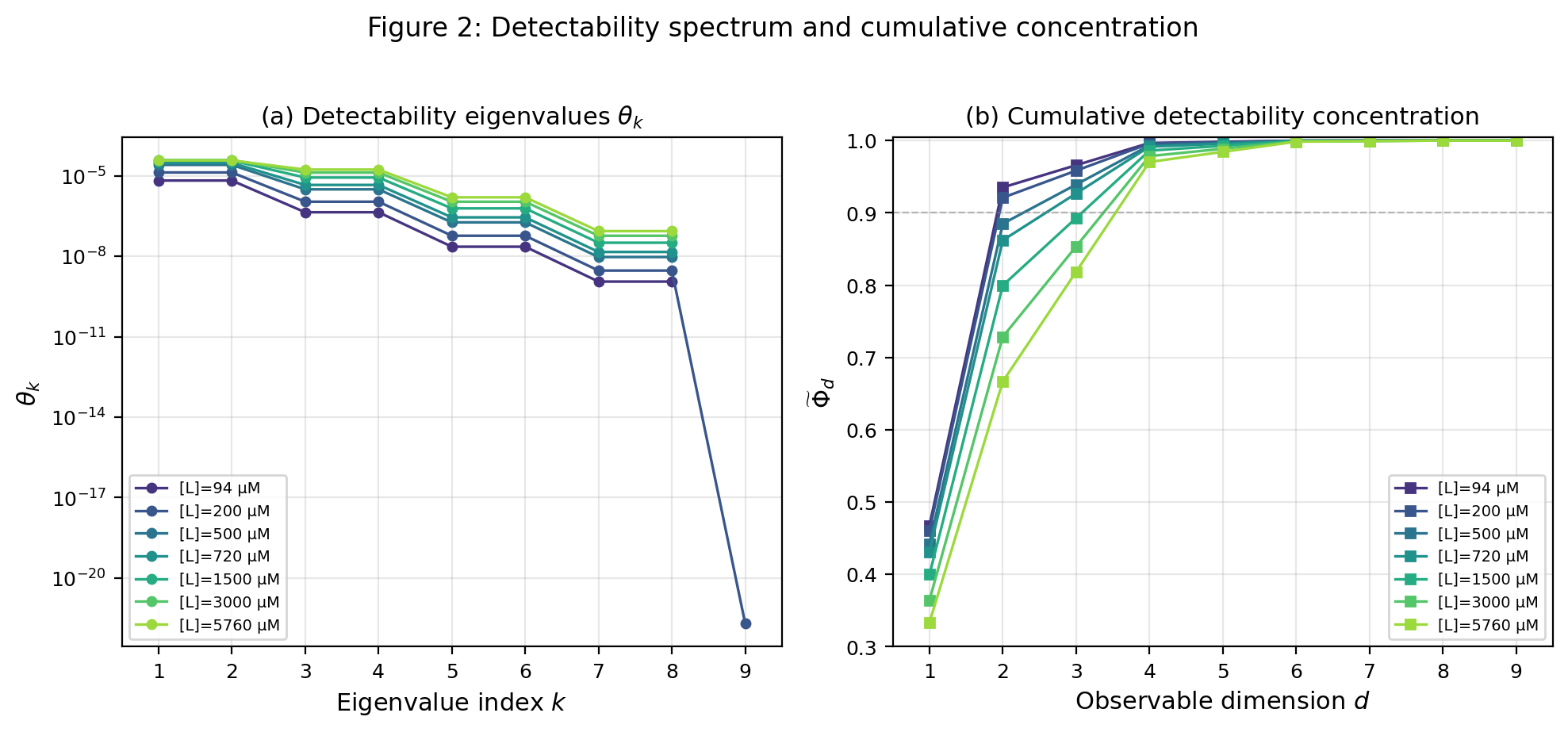
As in the previous worked examples, raw visibility and backbone-normalised detectability do not coincide, as shown in Figure 15. The top detectability eigenvalue rises from about
| (11.43) |
at to a peak near
| (11.44) |
around , while the detectability stable rank grows from about to in the present backbone-normalised scaling. In cumulative terms, one raw direction suffices for retention over most of the adaptive regime, whereas the backbone-whitened concentration typically requires two to four directions. The chemotaxis benchmark therefore reinforces, in a mechanistically different setting, the main message of Section 6: the visible signal and the statistically distinguishing signal against the detailed-balance backbone are related, but they are not the same geometric object.
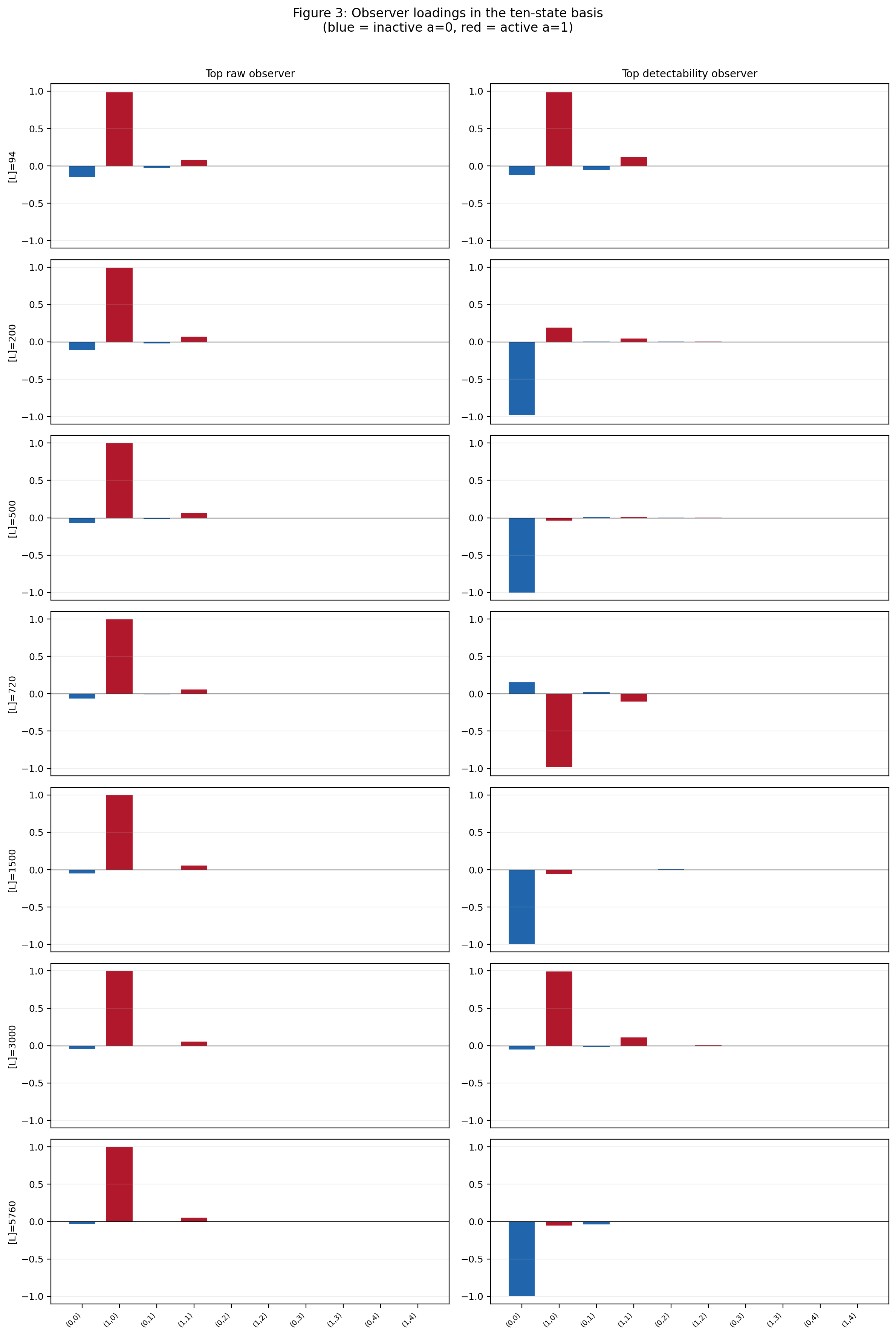
The leading observer directions remain interpretable rather than diffuse. Figure 16 shows that the dominant raw observer is concentrated almost entirely on the lowest methylation level, as an activity contrast between and , with only a small secondary correction at . The detectability-optimal direction is broader and more ligand-dependent: in some regimes it is dominated by the inactive low-methylation state , in others by the active low-methylation state , with smaller balancing weight on or . This is the pattern one expects when the raw nonequilibrium correction is nearly rank one but the detailed-balance backbone is anisotropic.
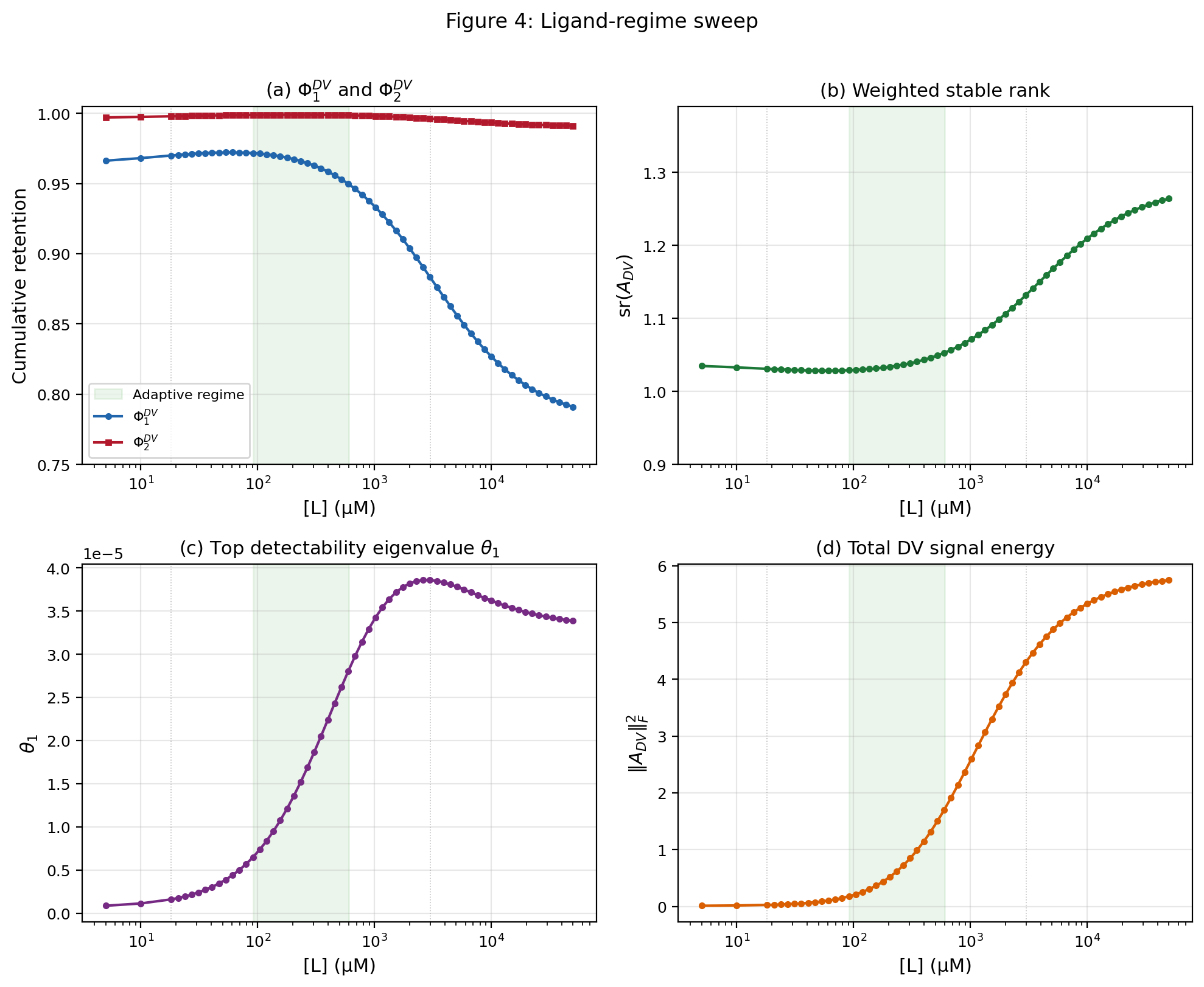
The continuous ligand sweep in Figure 17 makes the operating-point dependence clear. Inside the adaptive window, the raw signal is most concentrated:
| (11.45) |
As rises through and beyond , the rank-one retained fraction decays smoothly toward about , while remains close to , the weighted stable rank rises only to about , and the total DV signal energy grows monotonically before saturating. There is no sharp spectral transition at the edge of the adaptive regime. The geometry changes gradually with ligand level rather than catastrophically.
The methylation validation in Figure 18 is important for interpretation. The source model operates in a regime where the stationary methylation marginals remain extremely similar across ligand values, even when the mean activity changes appreciably. The finite-observation result is therefore not that the methylation memory is broad and low-rank. It is subtler. The raw nonequilibrium correction is sharply concentrated even though the methylation marginals themselves are almost indistinguishable. This explains why the dominant observer localises on a low-methylation activity contrast rather than on a broad redistribution over all methylation levels.
Taken together, the Sartori benchmark strengthens the empirical recurrence case in a more demanding state space than Banerjee. The model is mechanistically distinct from both proofreading and chemomechanical transport, and its reduced Fisher space has dimension nine rather than four or five. Yet the raw finite-observation geometry remains strongly compressed throughout the tested ligand family. At the same time, the benchmark preserves the same structural lesson already seen in the earlier biological examples: detectability is broader than raw visibility, and the leading observer directions remain physically interpretable. The correct conclusion is therefore not that every aspect of chemotactic memory is low-dimensional. It is that, in this source-locked ten-state feedback receptor model, the Donsker–Varadhan correction itself has a sharply concentrated spectral front. What remains open for this benchmark is a matched-null control family comparable to the kinesin negative-control analysis; until that is in hand, the chemotaxis example should be read as a source-locked worked example rather than as evidence that sensory-feedback architecture generically enforces low rank.
12 Related-work connections
12.1 Estimators, hidden events, and coarse observation
A large part of the partial-observation literature studies estimator quality, lower bounds, hidden events, unresolved transitions, and coarse-graining schemes for irreversibility detection [5, 13, 6, 7, 8, 9, 10, 11, 43, 36]. Those works ask how much irreversibility can be inferred from restricted data.
The present paper addresses a complementary question. Alongside asking which estimator is best, one can ask how much nonequilibrium signal the chosen observable sector can retain in principle. In the regime treated here, that question is governed by a weighted spectral envelope, its hidden share is the spectral tail, and observer quality is controlled by alignment with the singular front of the correction. The Gaussian shadow divergences studied here are local observed-Gaussian comparison laws, conceptually adjacent to trajectory-level irreversibility measures such as Roldán–Parrondo, but not the same object.
12.2 Observer dependence, coarse graining, and design
Restricted-information and coarse-grained thermodynamic frameworks emphasise that observation is part of the thermodynamic problem itself [19, 20, 8, 17, 18]. Work on current fluctuations, random counting observables, and optimised coarse-graining schemes makes the same point from a design perspective: some observations are much better than others for irreversibility detection [15, 14, 16].
The alignment and shadow theorems make that statement concrete in the present setting. A visibility-optimal observer aligns with the singular front of the raw signal. A detectability-optimal observer aligns with the singular front of the backbone-whitened signal. The theory therefore gives a geometric ranking of observers rather than only a qualitative statement that coarse observation can help or hurt.
12.3 Conceptual and geometric context
Several neighbouring literatures sharpen the conceptual space. Frenesy and time-symmetric dynamical activity make clear that nonequilibrium structure is richer than entropy-production rates alone [44]. Conditioned-process theory shows how distinct microscopic dynamics can collapse onto equivalent effective descriptions under large-deviation tilts [45].
Spectral work on nonreversible chains shows that singular-value and gap objects can carry operational content rather than serving as linear-algebraic decoration; in the present context such gap control helps set the scale of the detailed-balance backbone against which the weighted signal is read [46]. The cycle-current perspective of Schnakenberg and Andrieux–Gaspard clarifies the physical source of the skew sector, while reversible-chain information geometry provides a natural detailed-balance backdrop for the Fisher-coordinate formulation used here [30, 31, 28]. We also note a nearby geometric literature around Souriau’s Lie-group thermodynamics and Barbaresco’s Souriau-Fisher information geometry [47, 48, 49].
Taken together, these neighbouring literatures locate the results clearly. The paper is complementary to work on bounds, estimators, and coarse-grained thermodynamics. Its specific contribution is a finite-dimensional visibility law for the Donsker–Varadhan correction in the Markov Gaussian regime, together with its observer geometry, shadow criterion, and ordered spectral readout.
13 Scope
13.1 What is proved
Within this setting, the Donsker–Varadhan correction is identified as a positive weighted correction operator generated by the reduced skew channel and factorising through the weighted signal operator and the detailed-balance backbone. Within its stated Gaussian and orthogonal-observer scope, the theory gives the visibility law, the full envelope hierarchy, retention fractions, hidden tail, stable-rank obstruction, alignment formula, optimal and generic orthogonal observers, the shadow formulas, and the backbone-whitened detectability reformulation. In particular, the envelope hierarchy determines the eigenvalue profile of , equivalently the singular-energy profile , while the shadow hierarchy supplies the distinct spectrum relevant for Gaussian distinguishability.
The abstract weighted-geometry theorem also holds in finite dimension. It is a transfer theorem: once a positive semidefinite correction admits a weighted Gram factorisation relative to a positive-definite metric, the envelope, alignment, detectability, and spectral-readout machinery transfer by Euclideanisation. This includes BKM-symmetrised operator space.
What is not proved here is equally important. Projection suppression and shared observed-Gaussian behaviour are asymptotic Gaussian corollaries, not new bridge theorems. The exact separation proved here is a Hessian-level statement, and beyond quadratic order the paper does not rule out mixed dissipative-skew terms in the full rate function. The linear quantum extension is only at the level of weighted geometry transfer. It is therefore a conditional geometric framework rather than a tested model-specific theory, since no concrete quantum correction operator with the required structure is exhibited here. The full nonlinear quantum fluctuation bridge remains open.
13.2 Falsification
At the classical bridge level, the theory would fail if the reduced-coordinate correction were not representable as a weighted Gram signal built from the skew sector and the detailed-balance backbone. Numerically, the bridge claim fails if a direct computation gives above tolerance. The bridge identity is therefore a genuine key step.
At the finite-observation level, the envelope law would fail if direct optimisation over orthogonal rank- projectors did not agree with the singular-energy formula for , or if finite observation in the relevant fluctuation geometry were not correctly modelled by orthogonal compression on the reduced Euclidean Fisher space. In other words, if the physically relevant observable sectors could not be represented in this way, then the visibility law would no longer be the correct model.
At the statistical level, the Gaussian shadow package fails if KL, Hellinger, or total-variation quantities computed directly from the compressed Gaussian covariances do not match the spectral formulas in the shadow operator. At the same time, the equilibrium-shadow theorem is only a Gaussian theorem. It would be falsified as a general statement about observed nonequilibrium if the relevant finite-observation signatures in a given system were dominated by strongly non-Gaussian effects outside the quadratic regime, even when the projected Hessian correction is small.
At the spectroscopy level, the claim fails if the envelope increments do not reproduce the nonzero spectrum of , or if the -whitened Ky Fan values do not agree with the generalised-eigenvalue detectability spectrum.
Finally, the operator-space extension would fail as a physical theory if no meaningful linear fluctuation correction in BKM geometry could be identified for the relevant quantum nonequilibrium setting. The weighted transfer theorem would remain mathematically true, but it would lose physical force.
13.3 What the worked examples support, and what they do not
The worked examples play a calibrating role. They show that the distinction between raw visibility and backbone-normalised detectability remains informative across mechanistically distinct nonequilibrium models. In this empirical arc, the ribosome benchmark provides utility together with restraint, because the matched null shows that low-rank concentration in a small five-state system should not by itself be read as architecture-specific specialness. The kinesin benchmark is the stronger cross-domain recurrence case: it shows robust low-rank concentration at low load together with physically sensible broadening near stall under direct cycle competition. The chemotaxis benchmark is the larger-state-space stress test: it indicates that the same operator theory can remain informative beyond the smallest reduced spaces.
At the same time, the examples do not yet prove a universal low-rank law definitively. They support repeated utility of the two-spectrum framework, and they support cross-domain recurrence of the visibility geometry in the tested regimes, but they do not by themselves settle how much of the observed concentration is controlled by model class, operating regime, state-space dimension, or the number of effective irreversibility-injection channels. That wider question remains open.
Appendix I sharpens this point analytically. A homogeneous driven ring gives a clean counterexample to the naïve idea that few cycles should force low raw stable rank, while a finite-rank skew channel gives an exact bounded-complexity mechanism. Taken together, these results show that the relevant control variable is not bare cycle count by itself but the spectral localisation of the skew sector relative to the detailed-balance backbone.
Read laterally, the examples also sharpen the hidden-engine anatomy proved in the main text. What survives finite observation is organised by the same ladder in every case: skew source, detailed-balance transmission geometry, backbone-weighted visible signal, hidden return or hidden tail under rank constraint, and detectability after whitening.
13.4 What remains open
The first open direction is noisy observation-channel design. Section 6 gives a Gaussian shadow theorem for fixed linear noisy channels, but the optimisation problem over channels remains open. This is naturally an optimal experimental-design problem in the observed covariance geometry. Unlike deterministic subspace observation, the observation matrix enters nonlinearly in both the covariance defect and the backbone normalisation, so the design problem is no longer a direct Ky Fan optimisation. A related structural question is which backbone heterogeneities or projection mismatches force the detectability spectrum to broaden relative to the raw visibility spectrum.
The second open direction is the full nonlinear quantum bridge. The weighted operator-space extension shows that the visibility geometry is ready once the fluctuation correction is identified, but that identification remains to be derived beyond the linear regime.
The third open direction is extension beyond finite-state Markov models. Recent work on thermodynamically consistent coarse graining across particle and field descriptions suggests that structure can survive substantial change of description [50]. At the same time, the need to coarse grain empirical densities and currents in continuous space makes clear that observation scale must remain part of the structure rather than an external nuisance [51, 56, 52]. A natural question is whether a useful finite-observation complexity invariant, perhaps weighted stable rank or a field-theoretic analogue, survives renormalised coarse graining.
The fourth open direction is the non-Markov and driven large-deviation frontier. Periodic level-2.5 theories and recent non-Markov self-interacting large-deviation results suggest that empirical-measure and current structures persist well beyond the time-homogeneous Markov class treated here [53, 54]. It is therefore natural to ask whether an analogue of the weighted signal operator and its finite-observation envelope exists for memoryful or periodically driven systems.
The fifth open direction is implementation. The envelope hierarchy suggests a direct route to irreversibility spectroscopy: estimate the singular front of the nonequilibrium signal from controlled families of observables or from designed operator-space compressions. A natural next step is to study how robustly the leading singular front of can be estimated from finite data under partial observation. A closely related frontier is active or response-based detection, where recent finite-frequency fluctuation-response bounds indicate that nonequilibrium detectability can also be organised in the frequency domain [55]. In the background sits the broader tension between spectral structure and scalar uncertainty bounds, now familiar from the thermodynamic uncertainty-relation literature [24, 25].
13.5 Conclusion and outlook
The main results of this paper are finite-dimensional and specific to the Donsker–Varadhan correction, but their significance is broader. The central lesson is that finite observation does not merely discard information. In the present setting it organises nonequilibrium structure into an exact visible geometry. In the present setting that geometry is carried first by the weighted signal operator , which governs raw visibility, and second by its backbone-whitened detectability counterpart, which governs Gaussian distinguishability relative to the detailed-balance backbone. This yields an exact theory of nonequilibrium visibility, observer design, detectability, and spectral readout under explicit rank constraints.
That exact core is already enough to support a strong conclusion, but the conclusion must be stated at the correct level. We do not merely have a collection of examples with similar numerics. We have identified a common mathematical form. Across the finite-dimensional class treated here, nonequilibrium fluctuation structure is governed by a positive weighted correction operator, its weighted signal factorisation, its Ky Fan envelope hierarchy, and a second backbone-normalised spectrum for detectability. Within the orthogonal-observer model, the envelope hierarchy is the exact rank-constrained visibility law generated by . It determines the singular-energy profile , and within the finite irreducible Markov Gaussian setting treated here this weighted geometry is the organising structure.
The sharper question is where a low-rank regime sits inside that exact geometry. The worked examples show recurrent concentration, but Appendix I makes clear that low-rank concentration is not a theorem of the whole class. A homogeneous driven ring has raw weighted stable rank
| (13.1) |
so topological simplicity by itself does not force raw spectral simplicity. By contrast, if the reduced skew channel has rank at most , then both raw visibility and backbone-whitened detectability have rank at most . This isolates one exact bounded-complexity mechanism. The recurrent concentration seen in the biological benchmarks is consistent with a regime in which the skew channel is effectively localised to a small number of irreversibility-injection directions, although the paper does not prove that benchmark by benchmark. The natural conclusion is therefore not that every finite nonequilibrium system is low-rank, but that the low-rank behaviour seen in the worked examples belongs to a candidate regime inside the exact weighted geometry.
We therefore state the conclusion in its disciplined form: this work identifies the exact weighted geometry of finite observation and separates two optimisation problems that are often conflated, raw visibility and backbone-normalised detectability. It also provides evidence for a candidate low-rank universality regime within that geometry.
What recurs across model classes is not merely the fact of compression. It is the same organising architecture: skew source, detailed-balance transmission geometry, weighted visible signal, hidden tail under rank constraint, and backbone-whitened detectability. The worked examples, together with the analytic boundary note, show that the open problem is now sharply posed. The relevant control variable is not bare cycle count alone. It is how broadly the skew sector is transmitted across the backbone modes.
That point matters for the next stage of the programme. The task is no longer to ask vaguely whether low-rank concentration appears again. The task is to determine which structural features keep the transmitted skew sector spectrally localised, which features delocalise it, and how the basin should be organised. Upgraded matched nulls, controlled scaling families, and explicit breakdown classes are the natural next tests.
The frontier is therefore clear. The finite-dimensional theory is solved at the structural level. The low-rank regime is strongly suggested in a nontrivial empirical arc, but it is not yet the whole class. If the basin analysis now underway confirms that the same low-rank regime persists under broader structural sweeps, then finite observation will not merely be a practical limitation on what can be seen. It will pick out a genuine organising regime of nonequilibrium structure.
Appendix A Reduced-coordinate identities
This appendix records the reduced-coordinate identities underlying the bridge theorem. The aim is to place the key algebra in one location so that the main text remains readable. It is the same reduced conductance-and-skew decomposition used in Section 3, written here in the explicit variables of the envelope expansion.
A.1 Reduced tangent coordinates
Let
| (A.1) |
and let be an orthonormal frame of , so that
| (A.2) |
Every tangent fluctuation is written uniquely as with .
In these coordinates, the Fisher-conjugated generator reduces to
| (A.3) |
with
| (A.4) |
The canonical detailed-balance reference Hessian on the same reduced space is
| (A.5) |
A.2 Reduced envelope structure
Write the Donsker–Varadhan variational formula as [1, 2, 3]
| (A.6) |
Choose reduced Fisher coordinates and reduced logarithmic coordinates by
| (A.7) |
Expanding the variational integrand to second order gives
| (A.8) |
Because , the conductance block depends only on . Hence
| (A.9) |
Setting , one has
| (A.10) |
Completing the square in yields
| (A.11) |
Therefore
| (A.12) |
Since , one gets , and hence
| (A.13) |
Equivalently,
| (A.14) |
A.3 Absence of mixed terms
The quadraticity theorem can be read as a cancellation statement. A generic two-sector reduced envelope would allow mixed terms involving both the dissipative and skew sectors in the Schur complement. The identity removes those terms because the conductance arises from the quadratic form in the auxiliary variable, and a skew matrix has zero quadratic form. The result is that the correction depends quadratically on the skew sector and is weighted only by the inverse detailed-balance backbone. This is the algebraic source of the weighted signal form
| (A.15) |
A.4 Observed block formula
Let be a rank- orthogonal projector whose range is -invariant, and choose a basis adapted to the splitting
| (A.16) |
so that is block diagonal:
| (A.17) |
Then
| (A.18) |
Its slow block is therefore
| (A.19) |
This is the converter formula used in Section 3.
Appendix B Linear algebra of weighted signal operators
B.1 Visibility interval
Let be any finite matrix with singular values
| (B.1) |
For a rank- orthogonal projector , define
| (B.2) |
Then Ky Fan gives
| (B.3) |
and the minimum is
| (B.4) |
with the convention that zero singular values fill out the list if .
Applied to
| (B.5) |
this gives the full visibility interval for rank- observation:
| (B.6) |
B.2 Optimal hidden tail
The optimal hidden residual after rank- observation is
| (B.7) |
This is the Eckart-Young residual in Frobenius norm, expressed at the signal level. In the present paper it is the irrecoverable hidden nonequilibrium tail under the best rank- observer.
B.3 Stable-rank obstruction
For any nonzero matrix ,
| (B.8) |
Then
| (B.9) |
Dividing by gives the basic stable-rank obstruction
| (B.10) |
B.4 Direct-sum envelope law
If
| (B.11) |
is block diagonal with respect to an orthogonal splitting, then the rank- envelope satisfies
| (B.12) |
where denotes the Ky Fan top-singular-energy envelope [32]. This expresses optimal budget allocation across independent sectors.
Proof.
The singular values of are the multiset union of the singular values of and . The optimal sum of the top squared singular values is obtained by distributing the rank budget between the two blocks in the best possible way. ∎
B.5 Comparison of weighted and unweighted envelopes
Let be positive definite with eigenvalue window
| (B.13) |
Then
| (B.14) |
Hence for
| (B.15) |
one has
| (B.16) |
Taking optimal compressed traces gives
| (B.17) |
Appendix C Random projector calculations
C.1 Expectation of a Haar projector
Let be Haar-uniform among rank- orthogonal projectors on . Then orthogonal invariance implies
| (C.1) |
for some scalar . Taking traces gives
| (C.2) |
hence
| (C.3) |
C.2 Expected retained signal
For any fixed matrix ,
| (C.4) |
Applied to the weighted DV signal,
| (C.5) |
C.3 Expected directional overlap
For any fixed unit vector ,
| (C.6) |
Thus each singular direction of the signal is seen at the same average rate by a generic rank- observer.
C.4 Remark on concentration
The present paper only needs the mean baseline. If desired, concentration of and of around their means can be obtained from standard concentration on the Grassmannian. We omit those estimates because they are not needed for the main results.
Appendix D Gaussian comparison formulas
This appendix records the centred Gaussian formulas used in Section 6.
D.1 KL divergence
For centred Gaussian laws on with covariance matrices ,
| (D.1) |
In the shadow setting,
| (D.2) |
Hence
| (D.3) |
whose eigenvalues are , where are the eigenvalues of . This yields
| (D.4) |
Likewise,
| (D.5) |
whose eigenvalues are , giving
| (D.6) |
D.2 Hellinger distance
For centred Gaussians,
| (D.7) |
Substituting the detailed-balance and nonequilibrium observable covariances and factoring out gives
| (D.8) |
D.3 Pinsker and Bayes error
Pinsker gives
| (D.9) |
For equal priors, the optimal Bayes classification error satisfies
| (D.10) |
Combining these with the KL bound
| (D.11) |
yields the total-variation and Bayes-error estimates stated in Section 6.
Appendix E Worked details for the literature examples
This appendix records the precise interpretive use of the external literature discussed in Sections 11 and 12.
E.1 Four-state two-cycle benchmark
The worked benchmark of Section 11 uses the four-state, five-link, two-cycle network from Appendix E, Table IV of van der Meer, Ertel, and Seifert [37]. Two roles are separated carefully.
First, the paper uses the generator as a compact multicyclic test of the bridge, envelope, and shadow theorems.
Second, to connect directly to the source observation pattern, the paper defines the edge-induced rank-one sector
| (E.1) |
This is an orthogonal surrogate for the physical access pattern observe only the link. It is not a claim that the waiting-time estimator of [37] itself is literally an orthogonal projector on reduced Fisher space. The point is more disciplined: once one restricts to the theorem class of the present paper, is the canonical one-dimensional sector induced by the observed link within that class.
The numerical comparison in Section 11 therefore separates three quantities on the same benchmark family: raw retained nonequilibrium signal, backbone-normalised detectability, and the gap from the observed-link sector to the unconstrained optimal rank-one observers. The short forcing sweep is performed for this same induced sector, not for a re-optimised observer.
E.2 Estimator papers
In the finite-resolution and missing-data literature, the central practical question is how well one can estimate entropy production from restricted observations [57, 5, 6]. The present paper does not replace those estimators. It inserts a prior geometric question: how much of the weighted nonequilibrium signal is observable at all in the chosen sector? The retained fraction and the alignment gain are the relevant pre-estimation quantities.
E.3 Lumping and milestoning
The milestoning work of Blom et al. [13] shows that reprocessed coarse observation can improve dissipation estimation. The present theory interprets that phenomenon as better alignment with the singular front of the weighted signal, rather than as a paradox in which a coarser observation outperforms a finer one.
E.4 Unresolved events
Harunari’s unresolved-event framework [7] studies hidden irreversibility at the event-statistics level. The present paper addresses the same obstruction at the Gaussian Hessian level. These should be seen as complementary rather than competing approaches.
E.5 Observation-dependent thermodynamics
E.6 BKM and de Bruijn geometry
Appendix F Operator-space technicalities
This appendix records the Euclideanisation used in Section 9.
Let be a positive-definite metric on a finite-dimensional space . If is -orthogonal, then
| (F.1) |
is an ordinary Euclidean orthogonal projector.
Indeed,
| (F.2) |
Moreover,
| (F.3) |
Since is -self-adjoint,
| (F.4) |
so
| (F.5) |
Thus is Euclidean orthogonal.
If , define
| (F.6) |
Then the Euclideanised correction is
| (F.7) |
Hence the weighted projector problem becomes an ordinary Euclidean Gram problem after conjugation by .
Appendix G Interpretive viewpoint and proof-status boundaries
The finite-observation theory proved in the main text can be placed inside a slightly broader interpretive viewpoint, provided that the proof-status boundary is kept sharp.
The basic distinction is between structural invisibility and practical weakness. Structural invisibility is vertical: degrees of freedom are intrinsically unobservable because they lie in fibres that are annihilated by the observation map or by the first positive descended object. Practical weakness is horizontal: after the invisible directions are quotiented out, the descended positive object may still be spectrally weak or anisotropic on the active quotient. In the present paper, the relevant descended object is the Donsker–Varadhan correction , and the active quotient is the reduced Euclidean Fisher space fixed in Sections 2 and 3.
A small observed correction can arise for conceptually different reasons. It may arise because the observation genuinely kills the relevant directions, because the quotient signal is low-rank but aligned away from the chosen observer, because the quotient signal is broad and weak, or because the observable sector is simply the wrong thin slice through an otherwise informative quotient geometry. These are not the same mechanism.
The work proves one finite-dimensional branch of this broader viewpoint: once the finite-state Markov Gaussian setting is fixed, the nonequilibrium correction descends to a weighted positive object, its finite-rank visible mass is solved by the envelope hierarchy, and its backbone-normalised distinguishability is solved by the shadow spectrum. That is the scope established here.
The finite-observation picture can fail by structural fibre collapse, by quotient-rank or quotient-anisotropy failure, by mismatch between the chosen thin observer and the dominant quotient directions, or by genuinely nonlinear aliasing beyond the quadratic regime. These mechanisms should be kept distinct, rather than collapsed into generic talk of “information loss.”
Appendix H Interpretive synthesis for the worked examples
The theorems of Sections 3 to 7 admit a compact synthesis that is useful when reading the worked benchmarks.
The algebraic source of the nonequilibrium correction is the reduced skew channel . The detailed-balance backbone does not generate the correction by itself, but it supplies the transmission geometry through which the skew source becomes visible. The natural signal object is therefore the backbone-weighted operator
| (H.1) |
Finite observation compresses this weighted signal, not the full generator.
When an observed sector is -adapted, the block formula gives a second useful layer of anatomy:
| (H.2) |
The first term is the intrinsic observed correction. The second is the hidden mixed-return channel from the complementary sector, throttled by the inverse stiffness of the fast detailed-balance block. Thus hidden nonequilibrium is not a vague reservoir. On adapted sectors it has a return mechanism.
At finite observer rank , the optimally hidden budget is the singular-energy tail of the weighted signal operator,
| (H.3) |
so the envelope hierarchy is literally a spectroscopy of what finite observation cannot recover at the chosen rank. After whitening by the backbone, the relevant distinguishability object is the shadow or detectability spectrum. This is a second spectrum. It agrees with raw visibility only in special cases and should not be identified with it.
Taken together, the worked examples can be read through one recurring ladder: skew source, weighted signal, hidden return or hidden tail, and whitened detectability. This paper develops that ladder only for the finite-observation setting treated in the main text. Broader extensions are left outside the present scope.
Appendix I An analytic note on the scope of the low-rank universality claim
This appendix records two exact analytic complements to the worked examples. The first gives a clean boundary family showing that low raw stable rank is not forced by topological simplicity alone. The second gives an exact bounded-complexity mechanism. Together they clarify what the universality claim of the main text does and does not assert.
I.1 Homogeneous driven ring: broad raw visibility and bounded detectability
Consider the nearest-neighbour -state ring with uniform stationary law and homogeneous clockwise versus anticlockwise bias. On the mean-zero reduced Euclidean Fisher space, the detailed-balance backbone and reduced skew channel are, up to positive constants that cancel from stable-rank ratios,
| (I.1) |
where is the cyclic shift. Both operators are circulant, so they diagonalise in the Fourier basis. For the nonzero Fourier mode
| (I.2) |
one has
| (I.3) |
Proposition I.1 (Homogeneous driven ring: raw stable rank grows linearly).
For the homogeneous driven ring,
| (I.4) |
has squared singular values proportional to
| (I.5) |
Consequently,
| (I.6) |
In particular, a one-cycle family can have raw weighted stable rank growing linearly with state-space dimension.
Proof.
The Fourier diagonalisation gives the displayed singular-value formula immediately. Since
| (I.7) |
and the maximal value is attained at and equals , the stated stable-rank identity follows. ∎
Proposition I.2 (Homogeneous driven ring: detectability complexity stays bounded).
For the same family,
| (I.8) |
has singular values proportional to
| (I.9) |
Hence
| (I.10) |
Thus the same homogeneous ring that is broad in raw visibility remains bounded in backbone-whitened detectability complexity.
Proof.
The Fourier formula above gives the singular values. Using the classical identity
| (I.11) |
and the fact that the largest value is , we obtain the displayed formula. The limit follows from . ∎
Propositions I.1 and I.2 show that the two spectra of the paper can behave very differently even in the simplest analytically transparent family. A homogeneous one-cycle system can be broad in raw visible signal while remaining bounded in detectability complexity. The reason is that inverse-backbone weighting amplifies the lowest-wavenumber backbone modes and suppresses the high-wavenumber tail strongly enough that the detectability stable rank stays bounded even as the raw-visibility stable rank grows linearly. The relevant control variable is therefore not bare cycle count by itself.
I.2 Finite-rank skew channels as an exact bounded-complexity mechanism
The next observation isolates a clean mechanism that does force bounded complexity.
Lemma I.3 (Finite-rank skew channels force bounded complexity).
If the reduced skew channel satisfies
| (I.12) |
then
| (I.13) |
and therefore
| (I.14) |
Proof.
Since is positive definite on the reduced space, both and left multiplication by are invertible. Hence
| (I.15) |
The stable-rank bounds follow from for every finite matrix . ∎
A useful special case is when the skew channel is generated by a fixed number of elementary antisymmetric couplings,
| (I.16) |
with orthonormal or merely linearly independent pair directions . Each summand has rank at most , so the hypothesis of Lemma I.3 holds automatically. This gives an exact mechanism by which localised irreversibility injection keeps both visibility and detectability spectrally compressible, uniformly in ambient state-space dimension.
The conclusion for the universality discussion is precise. The exact weighted geometry of finite observation is common across the full class treated in the main text, but low-rank concentration belongs to a narrower regime inside that geometry. The analytic boundary family above shows that low rank is not forced by topological simplicity alone. The finite-rank skew lemma shows that one sufficient bounded-complexity mechanism is spectral localisation of the skew sector. This is the structural axis that the next empirical appendix programme should probe.
Acknowledgements
No external funding was received. All work was produced independently without affiliation.
Author’s email is contact@nomogenetics.com.
References
- [1] M. D. Donsker and S. R. S. Varadhan, Asymptotic evaluation of certain Markov process expectations for large time. I, Communications on Pure and Applied Mathematics 28 (1975), 1–47.
- [2] M. D. Donsker and S. R. S. Varadhan, Asymptotic evaluation of certain Markov process expectations for large time. II, Communications on Pure and Applied Mathematics 28 (1975), 279–301.
- [3] H. Touchette, The large deviation approach to statistical mechanics, Physics Reports 478 (2009), 1–69.
- [4] J. L. Lebowitz and H. Spohn, A Gallavotti–Cohen-type symmetry in the large deviation functional for stochastic dynamics, Journal of Statistical Physics 95 (1999), 333–365.
- [5] M. Baiesi, Y. Nishiyama, and G. Falasco, Effective estimation of entropy production with lacking data, preprint, 2023.
- [6] L. Fritz, M. Ertel, and U. Seifert, Entropy estimation for partially accessible Markov networks based on imperfect observations: role of finite resolution and finite statistics, preprint, 2024.
- [7] P. E. Harunari, Uncovering nonequilibrium from unresolved events, preprint, 2024.
- [8] R. van der Meer and K. Saito, Thermodynamic bounds and error correction for faulty coarse graining, preprint, 2025.
- [9] B. Ertel and U. Seifert, An estimator of entropy production for partially accessible Markov networks based on the observation of blurred transitions, Physical Review E 111 (2025), 044106.
- [10] J. Ehrich, Tightest bound on hidden entropy production from partially observed dynamics, Journal of Statistical Mechanics: Theory and Experiment (2021), 083214.
- [11] J. Degünther, J. van der Meer, and U. Seifert, Fluctuating entropy production on the coarse-grained level: inference and localization of irreversibility, Physical Review Research 6 (2024), 023175.
- [12] M. Esposito, Stochastic thermodynamics under coarse graining, Physical Review E 85 (2012), 041125.
- [13] K. Blom, H. Song, S. Vouga, R. Godec, and D. E. Makarov, Milestoning estimators of dissipation in systems observed at a coarse resolution, preprint, 2025.
- [14] R. Bao, N. Ohga, and S. Ito, Measuring irreversibility by counting: a random coarse-graining framework, preprint, 2025.
- [15] T. R. Gingrich, G. M. Rotskoff, and J. M. Horowitz, Inferring dissipation from current fluctuations, Journal of Physics A: Mathematical and Theoretical 50 (2017), 184004.
- [16] Q. Yu, M. P. Leighton, and C. W. Lynn, Coarse-graining dynamics to maximize irreversibility, preprint, 2025.
- [17] G. Teza, A. L. Stella, and T. GrandPre, Coarse-graining via lumping: exact calculations and fundamental limitations, preprint, 2025.
- [18] G. Teza and A. L. Stella, Exact coarse graining preserves entropy production out of equilibrium, Physical Review Letters 125 (2020), 110601.
- [19] G. Rubino, Č. Brukner, and G. Manzano, Coarse-grained quantum thermodynamics: observation-dependent quantities, observation-independent laws, preprint, 2025.
- [20] J. Pernambuco and L. C. Céleri, Geometry of restricted information: the case of quantum thermodynamics, preprint, 2026.
- [21] T. Lacerda, N. Bettmann, and J. Goold, Information geometry of transitions between quantum nonequilibrium steady states, preprint, 2025.
- [22] N. Bettmann and J. Goold, Information geometry approach to quantum stochastic thermodynamics, preprint, 2025.
- [23] F. Wirth, Exponential relative entropy decay along quantum Markov semigroups, preprint, 2025.
- [24] A. C. Barato and U. Seifert, Thermodynamic uncertainty relation for biomolecular processes, Phys. Rev. Lett. 114 (2015), 158101.
- [25] J. M. Horowitz and T. R. Gingrich, Thermodynamic uncertainty relations constrain non-equilibrium fluctuations, Nat. Phys. 16 (2020), 15–20.
- [26] J. Gu, Counterexamples to the conjectured ordering between the waiting-time bound and the thermodynamic uncertainty bound on entropy production, arXiv:2601.04039 (2026).
- [27] S. Ito, Stochastic thermodynamic interpretation of information geometry, Phys. Rev. Lett. 121 (2018), 030605.
- [28] G. Wolfer and S. Watanabe, Information geometry of reversible Markov chains, Information Geometry 4 (2021), 393–433.
- [29] C. Maes, K. Netočný, and B. Wynants, Steady state statistics of driven diffusions, Physica A 387 (2008), 2675–2689.
- [30] J. Schnakenberg, Network theory of microscopic and macroscopic behavior of master equation systems, Rev. Mod. Phys. 48 (1976), 571–585.
- [31] D. Andrieux and P. Gaspard, Fluctuation theorem for currents and Schnakenberg network theory, J. Stat. Phys. 127 (2007), 107–131.
- [32] K. Fan, Maximum properties and inequalities for the eigenvalues of completely continuous operators, Proceedings of the National Academy of Sciences 37 (1951), 760–766.
- [33] D. Petz, Monotone metrics on matrix spaces, Linear Algebra and its Applications 244 (1996), 81–96.
- [34] R. Bhatia, Matrix Analysis, Graduate Texts in Mathematics Vol. 169, Springer, New York, 1997.
- [35] M. Rudelson and R. Vershynin, Sampling from large matrices: An approach through geometric functional analysis, J. ACM 54 (2007), Article 21.
- [36] É. Roldán and J. M. R. Parrondo, Entropy production and Kullback–Leibler divergence between stationary trajectories of discrete systems, Physical Review E 85 (2012), 031129.
- [37] J. van der Meer, B. Ertel, and U. Seifert, Thermodynamic inference in partially accessible Markov networks: A unifying perspective from transition-based waiting time distributions, arXiv:2203.12020, 2022.
- [38] K. Banerjee, A. B. Kolomeisky, and O. A. Igoshin, Elucidating interplay of speed and accuracy in biological error correction, Proceedings of the National Academy of Sciences of the United States of America 114 (2017), 5183–5188.
- [39] F. Mosam and E. De Giuli, Heterogeneity dominates irreversibility in random Markov models, arXiv:2602.04905 (2026).
- [40] S. Liepelt and R. Lipowsky, Kinesin’s network of chemomechanical motor cycles, Physical Review Letters 98 (2007), 258102.
- [41] S. Liepelt and R. Lipowsky, EPAPS supplementary material for “Kinesin’s network of chemomechanical motor cycles,” supplementary document to Physical Review Letters 98 (2007), 258102.
- [42] P. Sartori, L. Granger, C. F. Lee, and J. M. Horowitz, Thermodynamic costs of information processing in sensory adaptation, PLoS Computational Biology 10 (2014), e1003974.
- [43] E. Meyberg, J. Degünther, and U. Seifert, Entropy production from waiting-time distributions for overdamped Langevin dynamics, Journal of Physics A: Mathematical and Theoretical 57 (2024), 25LT01.
- [44] C. Maes, Frenesy: time-symmetric dynamical activity in nonequilibria, Physics Reports 850 (2020), 1–33.
- [45] R. Chetrite and H. Touchette, Nonequilibrium Markov processes conditioned on large deviations, Annales Henri Poincaré 16 (2015), 2005–2057.
- [46] S. Chatterjee, Spectral gap of nonreversible Markov chains, The Annals of Applied Probability 35 (2025), 2644–2677.
- [47] J.-M. Souriau, Structure of Dynamical Systems: A Symplectic View of Physics, Birkhäuser, Boston, 1997.
- [48] F. Barbaresco, Geometric theory of heat from Souriau Lie groups thermodynamics and Koszul Hessian geometry: applications in information geometry for exponential families, Entropy 18 (2016), 386.
- [49] F. Barbaresco, Higher order geometric theory of information and heat based on poly-symplectic geometry of Souriau Lie groups thermodynamics and their contextures, Entropy 20 (2018), 840.
- [50] S. Mohite and H. Rieger, Thermodynamically consistent coarse-graining: from interacting particles to fields via second quantization, preprint, 2026.
- [51] C. Dieball and A. Godec, Mathematical, thermodynamical, and experimental necessity for coarse graining empirical densities and currents in continuous space, Physical Review Letters 129 (2022), 140601.
- [52] G. Falasco and M. Esposito, Macroscopic stochastic thermodynamics, Reviews of Modern Physics 97 (2025), 015002.
- [53] L. Bertini, R. Chetrite, A. Faggionato, and D. Gabrielli, Level 2.5 large deviations for continuous-time Markov chains with time periodic rates, Annales Henri Poincaré 19 (2018), 3197–3238.
- [54] F. Coghi, A. Budhiraja, and J. P. Garrahan, Level 2.5 large deviations and uncertainty relations for non-Markov self-interacting dynamics, preprint, 2026.
- [55] J. Zheng and Z. Lu, Thermodynamic and kinetic bounds for finite-frequency fluctuation-response, preprint, 2026.
- [56] C. Dieball and A. Godec, Perspective: Time irreversibility in systems observed at coarse resolution, The Journal of Chemical Physics 162 (2025), 090901.
- [57] U. Seifert, Stochastic thermodynamics, fluctuation theorems and molecular machines, Reports on Progress in Physics 75 (2012), 126001.